
Generative AI systems like ChatGPT have rapidly become everyday assistants for a wide range of knowledge work, from drafting emails to analyzing data. The skill of effectively communicating with these AI – known as prompt engineering – is now recognized as a key to unlocking their full potential (mckinsey.com). Prompt engineering is essentially the practice of designing and phrasing your inputs (prompts) in a way that produces useful, reliable outputs from the model. Just as better ingredients yield a better meal, better crafted prompts yield better AI results (mckinsey.com).
Why should general information workers care? Studies show that using AI tools can dramatically boost productivity for many tasks. For example, a recent MIT experiment found that access to ChatGPT helped professionals complete writing tasks ~40% faster while also improving output quality (news.mit.edu). In other words, learning to write good prompts can save significant time and produce more polished work. Businesses are taking note: McKinsey estimates generative AI could add up to $4.4 trillion annually to the global economy and potentially automate 50-70% of workers’ time spent on tasks (mckinsey.com, mckinsey.com). Prompt engineering is the interface between human intent and these powerful AI capabilities, making it a critical skill for the modern workforce. In fact, organizations are already hiring for “prompt engineer” roles and planning to reskill large portions of their workforce in AI use (mckinsey.com).
This guide provides a comprehensive, practical tour of prompt engineering. We will cover fundamental concepts (with scientific explanations), well-established prompting methods like zero-shot, few-shot, chain-of-thought (CoT), and ReAct, and then explore new creative prompting techniques that can help extract business value from large language models (LLMs). We’ll see how prompt strategies apply across industries – from increasing personal productivity, to supporting business decision-making and communication, to specialized uses in research and non-profits. Along the way, we include hands-on examples, illustrations, and step-by-step visuals to make the methods intuitive. The tone is conversational yet backed by research, with plenty of references (e.g., from arXiv, OpenAI, Anthropic, industry reports) to ground our advice in the science of LLMs. Whether you primarily use ChatGPT or other LLMs, the principles in this guide will be broadly applicable.
Let’s begin our journey by understanding what prompts are and why they matter.
2. Prompt Engineering Fundamentals
2.1 What is Prompt Engineering?
In simple terms, a prompt is the text (or other input) you provide to an AI model to instruct it or ask it for information. Prompt engineering is the deliberate crafting of these inputs to get optimal outputs (mckinsey.com). Unlike traditional software where you write code, when “programming” an LLM you use natural language instructions, examples, questions, and context. Prompt engineering has been called an art, but it’s increasingly grounded in science as we learn what kinds of prompts work best (ar5iv.org, ar5iv.org).
A prompt can be as basic as a single question, or a complex structured input containing multiple parts. For instance, with text models like GPT-4 or ChatGPT, a prompt might include a role or context, some data or examples, and a specific instruction or query. One research paper defines prompts as generally consisting of instructions, questions, input data, and examples (ar5iv.org). Not all prompts need all these parts, but clear instructions or questions are usually essential to elicit a useful response (ar5iv.org). In image generation models (e.g. DALL·E), prompts are descriptive text of the image you want, whereas for language models (LLMs) they often describe a task or query.
Think of a prompt as the conversation starter or task description you give the model. Prompt engineering, then, is figuring out how to say that in the most effective way. A well-engineered prompt can mean the difference between a rambling, irrelevant response and a highly accurate, concise one. It’s about guiding the model to understand exactly what you need. As McKinsey notes, skilled prompt engineers design inputs that “interact optimally” with the AI system’s knowledge, yielding better answers for tasks like writing marketing emails, generating code, analyzing text, engaging customers via chat, and so on (mckinsey.com).
In practice, prompt engineering ranges from choosing the right wording (“Translate the following text…”), to providing examples in the prompt, to specifying the output format (“Respond in JSON”). It may also involve setting a context or persona (e.g. “You are a helpful legal assistant…”). We’ll explore many of these techniques in the next sections.
2.2 Why Prompts Matter for LLMs
Large Language Models (LLMs) such as GPT-3, GPT-4, Google’s PaLM, Anthropic’s Claude, etc., are trained to predict text sequences. They have no direct programmatic understanding of a user’s intent; they rely entirely on the prompt to infer what you want. While these models are incredibly powerful – having absorbed vast knowledge during training – their output can vary hugely depending on how the prompt is written (mckinsey.com). A slightly rephrased question or added instruction can change the answer or its quality.
At a high level, modern LLMs leverage a phenomenon called in-context learning. This means they can learn to perform a task during the prompt itself, without updating their weights, simply by virtue of seeing instructions or examples in the prompt (medium.com). Unlike older NLP systems that needed fine-tuning on task-specific data, models like GPT-3 demonstrated that by scaling up model size, they become surprisingly good at adapting to new tasks just from prompts (arxiv.org). For example, GPT-3’s famous paper was titled “Language Models are Few-Shot Learners” because it showed that a 175B-parameter model, when given a few examples of a task in the prompt, could achieve high performance without any task-specific training (arxiv.org).
What does this mean for an information worker? It means that how you prompt is essentially how you program the AI. If you provide zero examples and just an instruction (zero-shot prompting), the model will attempt the task based on its general training. If you give a couple of examples of inputs and desired outputs (few-shot prompting), the model will infer the pattern from those and follow it (medium.com). If you ask it to “think step by step” or to critique its answer, it will try to do that too. The prompt is your way to exploit the model’s learned patterns and steer it toward the outcome you need.
Furthermore, LLMs have limitations like hallucinating facts or misunderstanding ambiguous requests. A well-crafted prompt can mitigate these issues by providing context or constraints. For instance, telling the model to cite its sources or to only use provided data can reduce made-up outputs. As one professor noted, prompt engineering is critical because it can prevent the model from “making up information” by constraining it properly (mckinsey.com). Researchers have found that augmenting prompts with relevant retrieved information significantly reduces knowledge hallucination (arxiv.org). In practice, this might mean copying a snippet from a source document into your prompt to ground the model’s answer (more on that in section 4.5).
Finally, it’s worth noting that prompt engineering is often an iterative process. You might start with a straightforward prompt, get a mediocre result, then refine the wording or add details and try again. This trial-and-error approach is normal – even recommended – when working with AI. OpenAI’s own best practices encourage starting simple and then iteratively improving the prompt based on the model’s output (medium.com, medium.com). Over time, as you see patterns in how the model responds, you internalize what works. The goal of this guide is to accelerate that learning by providing known techniques and examples.
2.3 Best Practices for Crafting Prompts
While there’s no single “right” way to write a prompt, several best practices have emerged that consistently help produce better results. Here are some general guidelines, supported by both anecdotal experience and research:
- Be Clear and Specific: Ambiguous or overly broad prompts often yield off-target responses. Clearly state what task or question the model is addressing. If you need a specific type of output, say so. For example, instead of asking “Give me advice on writing,” a clearer prompt would be: “Give me three tips for writing a college admission essay, focusing on tone and structure.” The latter defines the expected content (three tips) and scope (medium.com). Specificity helps the AI zero in on what you want.
- Provide Context or Details: If your task is about a particular scenario or text, provide the relevant info in the prompt. Models do not remember anything you haven’t explicitly given (outside of the conversation context). For instance, if you want a summary of a report, include the key points or sections of the report in the prompt, not just “summarize the report” with nothing else. Also, clarify the purpose or audience if relevant (e.g., “Summarize this report for a non-technical executive audience, in 200 words”). More context leads to more tailored and accurate answers (medium.com).
- Structure the Prompt for Readability: Long prompts can benefit from structure (headings, lists, separators) to help both you and the model. Use line breaks or delimiters (like
"---"or triple quotes) to clearly separate sections of the prompt, such as a block of input data versus the instruction (medium.com). Some prompters label parts of the prompt, e.g., “Context: … Task: … Output format: …”. While the model doesn’t “see” markdown formatting in a special way, these cues in natural language can still help it parse your intent. Think of it as making the instructions explicit and organized. - Show Examples (Demonstrations): A powerful approach is “show, don’t tell.” Instead of only describing the output you want, you can include one or more examples of the desired behavior. For instance, to teach a format, you might prompt: “Convert the following to JSON. Example:\nInput: Hello\nOutput: {“message”: “Hello”}\n Now do it for this input: Hi”. This few-shot style demonstration often leads to outputs that closely mimic the example format (medium.com). Use examples especially for complex tasks or when you have a very specific style/format in mind. (One caution: ensure your examples are correct and relevant, as the model will learn from them – garbage in, garbage out.)
- Guide Step-by-Step Reasoning if Needed: For complex problems that require reasoning or multi-step solutions (e.g., math problems, logical queries, or multi-part instructions), it helps to break down the task. You can explicitly instruct the model to follow a chain-of-thought (“First, analyze the problem… then solve step by step… finally give the answer”). We will discuss Chain-of-Thought prompting in detail shortly, but as a best practice, remember that the model will often do what you explicitly ask it to do in terms of process (medium.com). If you want a step-by-step solution, prompt that way.
- Specify the Output Format: If you need the answer in a particular format (a list, a table, JSON, an email draft, etc.), mention that in your prompt. For example: “List the top 3 priorities as bullet points.” or “Provide the answer as JSON with fields X, Y, Z.” LLMs are quite capable of producing structured text when asked. Providing a template or example output in the prompt can be even more effective (e.g., give a dummy JSON and ask to fill it in). Research on answer engineering highlights that controlling the answer shape (like demanding a certain format or length) is an important complement to prompt engineering (ar5iv.orgmedium.com).
- Avoid Ambiguity and Open-Endedness (Unless That’s What You Want): Broad prompts like “Tell me about climate change” will yield an extremely broad answer. If that’s not useful, narrow it down: “Explain the impact of climate change on coastal cities in 2-3 paragraphs.” On the other hand, for creative brainstorming you might intentionally use open-ended prompts. The key is to be aware of the prompt’s scope. If the output is too vague or generic, check if your prompt was too. Adding specifics or constraints can help.
- Use the Right Tone or Persona: LLMs will mirror the tone and style implied by your prompt. You can explicitly set a tone: “Respond in a friendly, informal tone.” Or assign a role: “Act as a professional career coach:” then ask your question. This can make outputs more consistent with what you envision. Many users of ChatGPT have found that starting the prompt with “You are a helpful assistant that…” can sometimes yield more reliable or on-point answers, effectively priming the model’s behavior (this leverages the system message concept, which we touch on later). Role prompting is a common technique to shape style and domain knowledge (ar5iv.org).
- Iterate and Refine: Don’t expect perfection on the first try for complex tasks. Treat each prompt attempt as an experiment. If the answer is off, analyze it: Did it misunderstand the question? Leave out part of the request? Then adjust your prompt. You might add a clarification (“If the user asks X, do Y, not Z”), or break the prompt into smaller pieces, or provide an example of a correct answer. One framework suggests starting zero-shot (no examples), then moving to few-shot if needed, then adding step-by-step guidance if needed (medium.com, medium.com). Each iteration teaches you more about how the model “thinks.”
Remember that prompt engineering is as much an art as a science – creativity can go a long way in phrasing an inquiry that the AI will handle well. In the next section, we’ll dive into concrete prompting methods that have been proven to work, which you can mix and match with the above general best practices.
3. Core Prompting Techniques
Now that we’ve covered the basics, let’s explore some core prompting techniques in detail. These are methods that have become well-known in the AI community, often through research papers that demonstrated their effectiveness. We’ll explain each technique, show how to use it, and discuss when it’s useful. The major ones we’ll cover are: Zero-shot and Few-shot prompting, Chain-of-Thought prompting, ReAct prompting, and a few other notable strategies like role prompting and self-critique. Understanding these will give you a strong toolkit for many situations.
3.1 Zero-Shot and Few-Shot Prompting
Zero-shot prompting refers to prompting the model without providing any example demonstrations – essentially, you just ask the question or give the instruction. For instance: “Translate this sentence to French: I love programming.” is a zero-shot prompt. You expect the model to perform the task based on its learned knowledge and understanding of the instruction alone. Zero-shot prompting is the simplest approach and works surprisingly well for many tasks, especially with modern instruction-tuned models (like ChatGPT) that have been trained to follow generic instructions.
Few-shot prompting means you include a few examples of the task within your prompt to show the model what you expect (medium.com). For example, your prompt might be:
Q: 2+2=
A: 4
Q: 3+5=
A: 8
Q: 7+6=
A:In this case, the model sees two examples of questions and answers (Q/A) for addition, and then is prompted with a new question. This was a technique highlighted in the GPT-3 paper, where they showed that providing even one or two examples (one-shot or few-shot) often dramatically improved performance on niche tasks (arxiv.org). The model essentially infers the task from the examples (“ah, we’re doing arithmetic addition”) and continues the pattern.
Why does few-shot help? It primes the model with the right context and format. It also reduces ambiguity – the model doesn’t have to guess what output style or approach you want; you’ve shown it. Few-shot prompting leverages the model’s in-context learning ability: the large model “learns” from the examples on the fly (medium.com). In essence, the prompt’s examples become a mini training set that the model conditionally bases its next output on.
A classic scenario: without examples, a model might misinterpret a request. For instance, the prompt “Write a summary of the article below.” might yield a summary that’s too long or not focused. If you instead prompt, “Article: [text]. Summary (in one sentence): [example summary]. Article: [new text]. Summary (in one sentence):”, you both clarify the task and format. The model is more likely to follow suit.
It’s important to note that few-shot examples should be representative and relevant. Using unrelated or misleading examples can confuse the model. Also, few-shot prompting consumes more of the model’s context length (tokens), so you have to balance how many examples you can include, especially if the input text is long. In practice, 1-5 examples are common; beyond that, it starts to significantly eat into context space, and returns diminish.
Few-shot prompting shines for tasks where you have a specific format or there’s potential for ambiguity in how to perform the task. For instance, if you want the model to answer in a certain structured way, providing a few Q&A pairs of that structure is very effective (medium.com). On the other hand, for very straightforward questions, zero-shot is often enough – modern models are quite capable zero-shot thanks to extensive instruction tuning.
To illustrate, let’s compare zero-shot vs few-shot in a simple case: extracting an email address from text.
- Zero-shot prompt: “Extract the email address from this text: ‘Please contact us at support@example.com for assistance.’” – The model might correctly answer: “The email address is support@example.com.”
- Few-shot prompt (with one example):
Text: "My email is john.doe@gmail.com"
Extracted Email: john.doe@gmail.com
Text: "Please contact us at support@example.com for assistance."
Extracted Email:Here we provided an example of what we mean by “Extracted Email”. The model will very likely output support@example.com directly, since the pattern is clear.
In summary, use zero-shot prompting for simplicity and when the task is clearly understood by the model, and use few-shot prompting when you need to demonstrate the task or format. Few-shot can significantly boost accuracy on tasks the model might not initially interpret correctly (ar5iv.org). As one survey puts it, few-shot prompting “uses k exemplars to prime the model” whereas zero-shot uses none, and few-shot is generally better when available (ar5iv.org). However, if the model is already well-instructed (like ChatGPT often is), you might be able to skip the examples and get good results zero-shot for many tasks.
3.2 Chain-of-Thought (CoT) Reasoning
One of the most celebrated techniques for improving LLM performance on complex reasoning tasks is Chain-of-Thought prompting, often abbreviated CoT. The idea is simple yet powerful: you prompt the model to generate a step-by-step reasoning process before giving the final answer (ar5iv.org). By making the model’s internal chain of reasoning explicit, you often get more accurate and explainable results, especially for math word problems, logic puzzles, or multi-hop questions that require connecting multiple facts (ar5iv.org).
In standard prompting, the model usually goes directly from question to answer in one leap (and might do reasoning internally, but invisibly). With CoT, you encourage it to articulate intermediate steps. A seminal paper by Google researchers in 2022 showed that CoT prompting enabled models like GPT-3 to solve significantly more complicated math word problems correctly, whereas they failed with direct prompts (ar5iv.org). Essentially, CoT “unlocks” latent reasoning abilities by asking the model to think out loud.
There are a couple of ways to implement CoT:
- Zero-Shot CoT: Simply append a phrase like “Let’s think step by step” to your prompt or question. For example: “Q: Roger has 5 tennis balls. He buys 2 more cans of tennis balls, each can has 3 balls. How many tennis balls does he have now? Let’s think step by step.” This cue often triggers the model to produce a multi-sentence reasoning breakdown before finalizing an answer. Amazingly, Kojima et al. (2022) found that even without showing examples, this phrase made the model start doing proper reasoning – hence “Zero-Shot CoT” (ar5iv.org).
- Few-Shot (Manual) CoT: Provide one or more examples in the prompt where you show a question and a worked-out reasoning process leading to the answer. Then ask the model a new question and it will imitate the process. For instance, you might show: “Q: [some puzzle]? A: First, I do this… Then that… Therefore the answer is X.” (two or three times with different puzzles) and then give a new Q. This was the approach in the original CoT paper by Wei et al. (2022) – they gave 8 examples of math problems with detailed solutions in the prompt, which dramatically improved accuracy (ar5iv.org). This is sometimes called “Manual CoT” because you manually write the reasoning exemplars.
Both approaches aim to get the model to output a reasoning chain. CoT is especially helpful for arithmetic word problems, logical inference, or problems where a direct answer is not obvious. It forces the model to break the problem into substeps. By externalizing the reasoning, errors can be caught in intermediate steps, and the final answer tends to be more grounded. Empirical results show CoT prompting can transform previously unsolvable questions into solvable ones for an LLM (ar5iv.org).
Let’s see a quick example to illustrate CoT vs standard prompting:
Without CoT: “Q: The cafeteria had 23 apples. They used 20 to make lunch and bought 6 more. How many apples do they have? A:”
A standard model might output something incorrect like “27” because it might mis-parse the question or just do a single operation (23 + 6 = 29, minus something? mistakes happen).
With CoT: “Q: ... How many apples do they have? Let’s think step by step.”
The model’s answer could look like: “They started with 23. They used 20, so 23-20 = 3 left. Then they bought 6 more, so 3+6 = 9. Therefore, they have 9 apples.” – and then possibly give the final answer “9”. This reasoning makes the solution clear and correct.Figure: Standard prompting vs. Chain-of-Thought prompting. In this example, a simple math word problem is answered incorrectly with a direct prompt (left), but correctly when the model is prompted to show its reasoning step by step (right). CoT helps guide the model through logical steps, yielding a correct answer with an explanation.
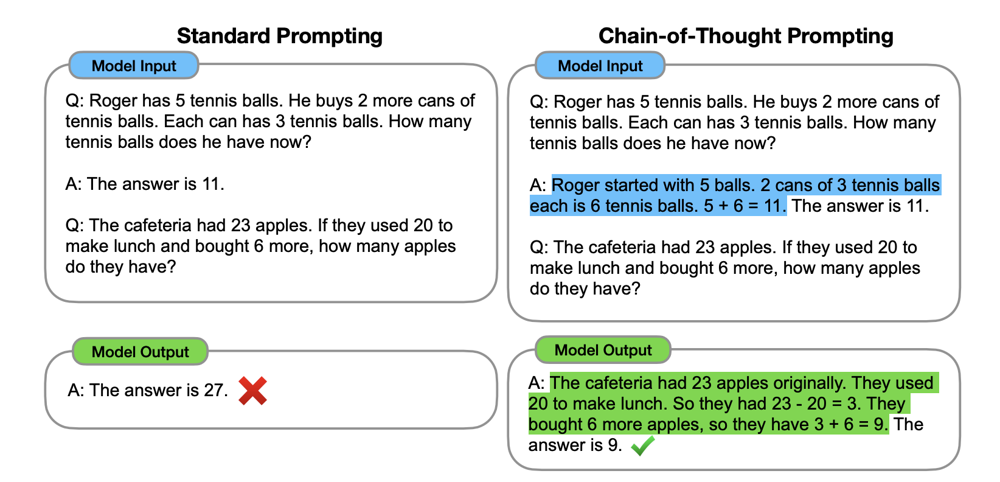
As shown above, CoT can greatly improve accuracy on multi-step problems by guiding the model through each step (ar5iv.org, ar5iv.org). It transforms the task into a sequence of small deductive steps, which LLMs handle better than a single giant leap.
A couple of notes and variations on CoT:
- Robustness and Self-Consistency: One issue is that if the model’s reasoning goes astray in CoT, the final answer will be wrong even if the approach was correct. Researchers introduced a method called self-consistency, where the model generates multiple distinct chains of thought and then the final answers are combined by picking the most common result【41†look 0 0】 (essentially a majority vote among the model’s own reasoning samples). This often yields more reliable answers because it reduces random reasoning deviations. Self-consistency is more of an inference technique (requires multiple model runs), so not something a user would do manually in a single prompt, but good to know it exists.
- Scaling with Complexity: For very complex tasks, even step-by-step can be tough. A recent idea is Tree-of-Thoughts (ToT) prompting (Section 4.5 will discuss this more) where the model explores a tree of possible steps or thoughts rather than a single linear chain (ar5iv.org). This is like branching out different approaches and then converging on the best answer. It’s advanced, but conceptually an extension of CoT.
- When not to use CoT: If you just need a straightforward fact or a simple answer, CoT might be overkill. Also, CoT can make responses much longer. For a quick answer, you might prefer brevity. Some models also might not respond to “Let’s think step by step” if they’ve been tuned to just give answers (though most still do, as it’s a learned pattern).
Overall, chain-of-thought prompting is a go-to technique for any problem that benefits from reasoning or explanation. Many users have found that even asking ChatGPT “Can you show your thought process?” leads to better outcomes in scenarios like coding or troubleshooting, because the model will lay out logic then reach a conclusion, rather than just guess an answer. CoT has been called a significant leap in harnessing LLM reasoning capabilities (ar5iv.org), and it’s a prime example of how a simple prompt tweak can unlock new performance.
3.3 ReAct (Reasoning and Acting) Prompts
As powerful as chain-of-thought can be, it still has a limitation: the model’s knowledge is confined to what’s in its internal parameters or the prompt. What if the model needs to use a tool or retrieve external information as part of solving a task? This is where ReAct prompting comes in – a framework that combines Reasoning and Acting in the prompt (promptingguide.ai ,promptingguide.ai).
The ReAct framework (proposed by Yao et al., 2022 (promptingguide.ai) encourages the model not only to think (reason) but also to take actions, such as making queries to an external system or calling an API, in an interleaved manner. In a ReAct prompt, the model generates a sequence of “Thoughts” and “Actions” and observes the results, then continues. Essentially, the model’s chain-of-thought is augmented with the ability to act on the world (like performing a web search, or looking something up) and then incorporate the result into its reasoning (promptingguide.ai, promptingguide.ai).
A classic example is a question answering scenario where the answer isn’t directly known by the model, but could be found via a web search. With a ReAct prompt, you might set up a format like:
- Thought: “I need to find information about X.”
- Action: “Search[X]” (meaning the model indicates it wants to perform a search)
- Observation: [Result of search]
- Thought: “Based on this info, …”
- Action: “Search[Y]” (another query if needed)
- Observation: [Result]
- Thought: “Now I have the needed info to answer.”
- Action: “Finish[ Final Answer: … ]”
The above is a schematic, but it shows the pattern. The prompt would include guidelines and possibly examples of this thought-act-observe loop (width.ai, width.ai). The LLM generates both the reasoning and the “API calls” (search queries, calculator usage, etc.), which are executed by some external logic, and the results fed back.
Why do this? Because it allows the model to overcome knowledge cutoffs or perform dynamic tasks. For instance, even the best trained model won’t know today’s weather – but a ReAct agent can perform an action “Search weather for [city]” and get the answer, then respond. In terms of prompt engineering, ReAct is about structuring the prompt and the conversation so the model knows it can output these special “Action” directives and that they will be handled.
From a practical point of view for an information worker: You might not manually implement a full ReAct loop in ChatGPT yourself (that would require you to read the model’s “Thoughts” and then do the search manually, etc.), but this approach underpins many LLM-based agents (like AutoGPT and others) that string multiple prompts together with tool use. It’s still worth understanding because it highlights how you can prompt the model to use external info. For example, you could prompt in plain language: “If you don’t know the answer, outline how you would find it.” The model might then produce something akin to ReAct steps (e.g., “Thought: I would search for X. [Since I cannot actually search, I’ll hypothesize the result] … therefore the answer might be Y.”). In doing so, it often reveals missing pieces or needed info.
Research has shown ReAct to improve factual accuracy and reduce hallucination, since the model can look up real data instead of guessing (arxiv.org, promptingguide.ai). On knowledge-intensive tasks (like open-domain QA) and decision-making tasks, ReAct outperformed chain-of-thought alone in the original paper (promptingguide.ai). The reasoning trace also makes the agent’s behavior more interpretable and trustworthy to humans (promptingguide.ai).
To make this concrete, imagine using a ReAct pattern in a prompt (simplified):
You are an assistant that can think and use tools.
When given a question, you will:
Think: analyze what to do.
Act: choose an action from [Search, Lookup] if needed.
Obs: show the result.
… (repeat Thought/Act/Obs as needed) …
Then give the final answer.
Question: Aside from the Apple Remote, what other devices can control the program Apple Remote was originally designed to interact with?
Thought 1: I need to find what program Apple Remote was designed for.
Act 1: Search[Apple Remote originally designed to control]
Obs 1: (Search result: "Apple Remote … originally designed to control the Front Row media center program …")
Thought 2: The program is Front Row. The question asks: aside from Apple Remote, what other devices can control Front Row?
Act 2: Search[Front Row media center other control devices]
Obs 2: (Search result: "Front Row can be controlled by Apple Remote or the keyboard function keys.")
Thought 3: Front Row is controlled by either the Apple Remote or the keyboard’s function keys.
Act 3: Finish[The program (Front Row) can be controlled by the keyboard’s function keys.]In this mock dialogue, the model was prompted to follow a ReAct format. It performed a search action, got an observation, reasoned further, and eventually finished with the answer: the keyboard’s function keys. This matches what the source likely said (and indeed, in Yao et al.’s paper example, that was the answer)【19†Lines 1-9】【19†Lines 25-33】.
The above is a bit technical, but it demonstrates how the model can interleave reasoning and tool use. The key for prompt engineering is: if you have a system where the model can take actions (via an API), you need to prompt it in a structured way to do so. If you’re just using ChatGPT by itself, you can’t have it actually search the web, but you can still use a hybrid approach: ask it what steps or external info would help, then you (the user) provide that info, and have it incorporate it. That’s effectively manual ReAct.
In summary, ReAct prompting expands what an LLM can do by coupling it with actions. From a user perspective:
- Use ReAct style if you have tools available (e.g., some interfaces let ChatGPT use plugins like web browser or calculator).
- Even without tools, you can mimic it by prompting step-by-step and injecting information yourself.
- The combination of CoT reasoning with actions leads to powerful LLM agents that can solve more complex tasks, plan multi-step solutions, and interface with external data( promptingguide.ai, promptingguide.ai). Many emerging applications (like AI assistants that schedule meetings or retrieve database info) rely on this paradigm behind the scenes.
For day-to-day use, you might mostly stick to plain prompting, but it’s good to know that under the hood, something like ChatGPT Plugins or Microsoft’s Bing Chat are using ReAct-like prompting to let the model call tools and then continue the conversation.
3.4 Other Notable Methods (Role Prompts, Self-Critique, etc.)
Beyond the big techniques above, there are a few other prompting methods and patterns worth knowing:
- Role Prompting (Persona-based prompts): We touched on this in best practices, but it’s a common technique to explicitly instruct the model to take on a role or persona relevant to your task. For example: “You are a financial advisor. A client asks: [their question]. Provide a helpful answer.” By doing this, you set the context and domain for the answer, often getting more appropriate detail. Role prompting can also be used to adjust tone (e.g. “You are a friendly customer service representative…”). In one taxonomy, this is considered a form of zero-shot prompt that provides contextual priming(ar5iv.org). It’s especially useful if the model tends to give generic answers – a role can anchor it to a perspective. ChatGPT system messages essentially do this behind the scenes (e.g., “You are ChatGPT, a large language model…”). For general info workers, don’t hesitate to assign the AI a role: “Act as my personal assistant,” “Act as a historian,” “You are an expert in Excel,” etc. It can change the style and content depth of the response.
- Self-Critique and Reflection: This method involves prompting the model to critique or check its own answer, and then potentially improve it. For instance, after the model gives an answer, you might prompt: “Please review the above answer for any errors or missing points and correct them.” Models like ChatGPT can often highlight weaknesses in their first attempt and refine if asked. There’s also a research technique called Reflection where the model is guided to internally reflect on its answer’s accuracy and coherence (ar5iv.org). The model basically does an introspective review: “Let me double-check if this makes sense…” and then revises. One can prompt this explicitly: “Provide your answer, then reflect on whether it could be wrong, and finally give a final answer.” According to recent literature, integrating such self-evaluation steps (the model acting as its own reviewer) can lead to more reliable outputs (ar5iv.org, ar5iv.org). Anthropic’s “Constitutional AI” is an example where the AI applies a set of rules (a kind of self-critique) to its outputs to make them safe and high-quality. In everyday use, a simple way to leverage this is a two-step prompt: “Answer the question. Then evaluate your answer and correct any issues.” This often yields an improved second answer.
- Prompt Decomposition (Least-to-Most Prompting): If a task is complex, you can break it into smaller sub-tasks via prompts. “Least-to-Most” prompting is a researched approach where the model first identifies simpler sub-questions, answers them, and then builds up to the big question(learnprompting.org). For example, if the question is “Should company X launch product Y in market Z?”, you might prompt the model to first list factors to consider, then analyze each factor (maybe in separate prompts or a single structured prompt), then have it weigh pros and cons, and finally have it conclude. Essentially, you orchestrate a chain of prompts, each addressing a piece of the problem. While this can be done interactively (you ask one part at a time), you can also sometimes do it in one prompt by instructing a sequence (“First do X. Once done, do Y. Then finally do Z.”). Decomposition is powerful for complex tasks because it aligns with how humans solve problems – tackle them step by step. This approach is behind many agent frameworks that plan tasks for the model. If ChatGPT gives a very convoluted or mixed answer, consider re-prompting by splitting the question.
- Ensemble Prompting (Ask multiple ways): This is not a single prompt, but a strategy. Sometimes you can run multiple different prompts that approach a question from different angles, and then either pick the best answer or even combine them. For instance, you might ask once in a straightforward way, once with a role prompt, and once with chain-of-thought, and compare the answers. Research has shown that an ensemble of reasoning paths (like self-consistency) can improve results【41†look 0 0】. For a user, doing this manually might be overkill, but if it’s an important query, you could double-check by rephrasing the prompt and seeing if the answer stays consistent. If not, that’s a sign to dig deeper. Some advanced usage involves prompting the model to generate several possible answers and then a final answer (majority vote), but current chat interfaces don’t easily allow multiple parallel generations without coding.
- Answer Formatting Tricks: Sometimes how you ask for the answer can coax the model into better performance. For instance, one approach for certain reasoning tasks is to have the model output answers in a structured format like a table, which can force it to be more precise and organized(ar5iv.org). Jin et al. (2023) introduced “step-by-step in a table” prompting, which improved reasoning consistency (ar5iv.org). Another trick if a model tends to waffle is to ask for an answer in the form of a list of points or a JSON with fields, which can reduce ambiguity. For example: “Provide the analysis as a JSON object with fields ‘Conclusion’ and ‘KeyEvidence’.” This limits where the model can go off-track. It’s a way of imposing a soft schema on the output through the prompt.
- “Do Nothing” Prompt: Humorous but sometimes useful – there’s a known prompt “When I say X, you say Y” to control output or “Don’t respond until I say ‘Go’”. This is a reminder that you can stage the conversation. You could feed a large chunk of text and then say “Do not respond yet. I will ask a question next.” so the model ingests a lot of data, then you send the question. In the single-turn prompt scenario, this equates to just putting all context before the question, but in a multi-turn chat you have flexibility. Tools like ChatGPT allow uploading content in one message and the question in the next, effectively.
- OpenAI Function Calling & Tools: A recent feature (for developers using the API) is to define “functions” that the model can call with JSON arguments. This is like a structured ReAct – the model can decide to invoke a function (e.g.,
lookup_weather(city="London")) and the system will execute it and return the result. This isn’t exactly a prompting technique but a tool feature; however, from the prompt engineering perspective, you must still phrase things such that the model knows when to call the function. It involves giving the model a brief of what functions do. While end-users of ChatGPT don’t see this directly, it’s good to be aware that the ecosystem is moving towards more tool-augmented prompting for reliability and capability.
To keep this section practical: As an information worker, two of the most immediately useful techniques here are Role prompting and Self-critique prompting. Start your prompts by setting a relevant role for the AI, and when needed, ask it to check or refine its answer. These alone can elevate the quality of output. Decomposing complex asks into smaller questions (either manually or instructing the model to do it) is another high-impact habit.
We’ve now covered the fundamental and well-known prompting methods. You can mix these as needed – for example, role + chain-of-thought (“As a detective, think step by step through this mystery…”), or few-shot + format specification. Prompt engineering often involves combining techniques to tackle the task at hand. In the next section, we’ll get creative and discuss some new or experimental prompting methods that go beyond these basics, with a focus on extracting business value and novel use cases.
4. Creative Prompting Methods for Business Value
The field of prompt engineering is evolving rapidly, and practitioners are constantly inventing new prompt strategies to solve specific problems. In this section, we introduce several creative or speculative prompting methods that can be particularly useful for business and professional contexts. These go beyond the standard techniques and venture into more imaginative uses of LLMs. Some are inspired by emerging research, while others are practical patterns that innovative users have tried. We’ll cover: Multi-Perspective prompts, Socratic self-questioning, Constraint-driven prompts, Iterative refinement loops, and Knowledge-augmented prompts. These techniques aim to help you squeeze more value from LLMs – whether it’s deeper insights, more reliable outputs, or efficient handling of domain-specific data.
(Note: While we present these as distinct methods, they can often be combined with the core techniques. Think of them as additional layers or recipes to apply for certain outcomes.)
4.1 Multi-Perspective & Role-Playing Prompts
One powerful way to enrich the output of an AI is to ask it to consider multiple perspectives or play multiple roles in answering a question. In a business setting, many decisions or analyses benefit from a 360-degree view – for example, understanding how a new policy might be seen by different departments, or how a product appeals to different customer segments. Multi-perspective prompting explicitly requests the model to generate insights from various viewpoints.
How to do it: You can formulate a prompt that sets up those different perspectives. For example: “Imagine how a CFO, a marketing director, and a frontline employee would each view the adoption of a new project management tool. Describe the concerns and interests of each.” In this prompt, the model will likely produce a structured answer, with sections for CFO, marketing director, and employee, each with their perspective. This is a way of leveraging the model’s ability to role-play multiple personas in one go. It can surface considerations that a single viewpoint might miss.
Another example: “Give me two contrasting analyses of this strategy: one from an optimistic viewpoint and one from a skeptical viewpoint.” This yields a balanced output where the model essentially debates or outlines pros and cons more distinctly by separating mindsets. It’s like getting a mini “red team vs blue team” analysis from one AI.
Role-playing prompts take this further by actually simulating a conversation or interaction between roles. For instance, you could prompt: “You are a product manager pitching a new idea to a skeptical executive. Write the dialogue of the PM explaining the idea and the executive asking tough questions.” The model can generate a back-and-forth dialogue. This method can be used to rehearse scenarios (like a Q&A session, an interview, a negotiation) where the AI plays all parties. It’s a form of self-dialogue that can reveal strong and weak points in an argument.
Why is this useful for extracting business value? Because business decisions often require understanding different stakeholders – be it employees, customers, or experts in different fields. An LLM, having digested perspectives from countless texts (management books, customer reviews, etc.), can mimic those viewpoints. While it’s not a substitute for actual stakeholder input, it’s a fast way to brainstorm potential concerns and angles. It might highlight, for example, that the CFO cares about cost and ROI, the marketing director cares about brand impact, and the frontline employee cares about ease of use and added workload – giving you a checklist of points to address.
To ensure coherent outputs, you might explicitly instruct formatting: “Provide the perspective of a CFO, CMO, and Software Engineer, each under a separate heading.” The model will likely follow that structure, making it easy to read.
Caveat: The model doesn’t truly have opinions – it’s pattern matching what such roles might say. So, use these outputs as brainstorming, not gospel. It’s also useful to specify if you want a certain balance (some models might have a bias to be either too optimistic or too critical). If you ask for contrasting perspectives, you naturally get balance.
This technique is creative in that you are essentially getting the model to simulate a group discussion or a set of different advisors. It taps into more of the model’s knowledge by not restricting it to one line of reasoning. In essence, you’re running several lines of reasoning in parallel via one prompt. An extension of this (in research, sometimes called “ensemble of experts”) is to have the model actually have a conversation with itself assuming different expert identities, and then come to a conclusion. In practical use, just listing perspectives often suffices.
Multi-perspective prompting can also generate new ideas. For example: “Consider the potential failure points of this project from the perspective of a pessimist, then suggest how to address them from the perspective of an optimist.” This yields both identification of risks and mitigation strategies.
In summary, to use multi-perspective prompts: explicitly name the roles or mindsets you want, and ask the model to respond for each. This creative approach can produce rich, multifaceted insights quickly, helping you anticipate issues and understand diverse considerations in business contexts.
4.2 Socratic Questioning and Self-Ask Prompts
Socratic questioning is a technique where, instead of directly answering a question, one asks a series of guided questions to arrive at the answer. You can leverage a similar idea in prompts: get the model to ask itself (and answer) relevant questions before finalizing a solution. This is somewhat related to chain-of-thought, but framed as a Q&A with itself.
Self-ask prompting might look like this: “Break down the problem by asking yourself smaller questions first. For example, first ask ‘What information do we have?’, answer it; then ask ‘What is being asked?’, answer it; then proceed to solve. Now apply this to the following problem: [problem].” This meta-instruction encourages the model to essentially play both student and teacher – formulating clarifying questions and then resolving them.
Another approach: “You are an analyst. First list any clarifying questions you’d want to ask about the task. Then, based on hypothetical answers, proceed to solution.” If the model generates clarifying questions, you can see what info might be missing or needed. If you actually have answers, you could provide them; if not, the model might make reasonable assumptions.
For instance, suppose you ask: “Should we expand our business to a new region?” A Socratic/self-ask approach might make the model respond with questions like “What is the demand in that region? What are the costs and risks? Do we have local expertise?” – and then it might go on to discuss each. This ensures a more thorough analysis. Essentially, the model is mimicking what a good consultant or critical thinker would do: not take a question at face value if it’s complex, but break it down into answerable components.
OpenAI researchers introduced a similar idea called “Self-Ask with Search” where the model explicitly asks a follow-up question that can be answered by a tool, then uses it. Even without a tool, just the act of posing a sub-question helps structure the reasoning.
Why this is valuable: It can result in a more nuanced answer and can surface hidden assumptions. For example, if you only asked “Should we do X?” the model might give a generic yes/no with some reasoning. But if you prompt it to question itself, it might identify factors you didn’t mention explicitly (“I’d want to know if market conditions are favorable”). This is great for analysis tasks – it’s like having an assistant who not only answers but also helps you figure out what questions to ask in the first place (something consultants are trained to do).
From a prompt perspective, you can do this in one go or interactively. One interactive way: User: “List some questions we should answer to make decision X.” Assistant: (lists questions). User: “Now, based on those, what would your decision be (if you had to guess the answers)?” This two-step approach allows you to simulate having all those answers.
To use it in a single prompt, you might combine it with chain-of-thought: “Think step by step. First, list any sub-questions. Then answer them one by one. Finally, give the conclusion.”
This method draws on the Socratic method (teaching by asking). It’s creative because you’re essentially instructing the AI to momentarily become both the one asking and answering. In doing so, it often uncovers details that a direct answer would skip.
One speculative but interesting extension: ask the model to debate itself. E.g., “Pose a tough question about the strategy, then answer it from a positive angle and a negative angle.” This can be seen as the model interrogating its own ideas.
Caution: if overused, the AI might generate unnecessary questions or get stuck in a loop. Keep the scope reasonable – for a moderate complexity question, maybe 2-3 sub-questions are enough.
In practice, Socratic prompting is a way to ensure thoroughness. It can be especially useful in research or analytical writing – you can prompt the model to essentially create an outline of questions to address, which you or the model can then fill in. It helps in problem decomposition, ensuring that the final answer is well-founded.
4.3 Constraint-Driven and Guided Output Prompts
Sometimes the challenge with LLM outputs is not creativity, but control. You may want to enforce certain constraints on the output for business reasons – e.g., a specific word count, avoiding certain phrases, maintaining confidentiality, or adhering to a style guide. Constraint-driven prompting involves baking such rules or criteria into your prompt so the model’s output stays within desired bounds.
Simple constraints can be directly stated: “Answer in no more than 100 words.” or “Do not mention our company name in the response.” Models often respect length instructions (though not perfectly). They also can follow “do/don’t” instructions to some extent, especially if phrased clearly up front. For example, “Draft an email to a client about the delay. Do: apologize sincerely and offer a new timeline. Don’t: blame the client or make excuses.” This gives the model a clear set of boundaries for content.
Another kind of constraint is format: “Your answer should be valid JSON only, with keys ‘Issue’ and ‘Recommendation’.” If you say this, many models will actually output just JSON. This is incredibly useful if you plan to feed the output into another system for post-processing (like extracting fields). It’s a way to have the model effectively structure data for you.
There’s also guided generation where you intersperse the prompt with some fixed text that the model must fill in. For example, “Subject: (write a subject line here)\n\nBody:\nDear [Name],\n… Sincerely,\n[Your Name]”. The model will fill the dots. Providing a template with placeholders is a strong way to enforce output shape. The prompt becomes part instructions, part skeleton of the answer.
A creative use of constraints is telling the model to follow a certain methodology or include certain factors. For instance: “Provide a SWOT analysis (Strengths, Weaknesses, Opportunities, Threats) of the proposal. Each section should be 1-2 sentences.” This not only forces structure but ensures the model covers all four aspects (it basically splits the task into four mini-tasks).
In research from OpenAI, they’ve explored techniques to reduce models’ hallucinations by implicitly constraining outputs – like instructing the model to say “I don’t know” if it isn’t sure, or to only use information from a given passage. You can do this too: “If the answer is not explicitly in the above text, respond ‘Not found in provided info.’” The model might then be more careful and not invent things outside the text.
One very business-relevant application: compliance and tone constraints. E.g., “Draft a response. It must be polite, and it must not promise anything we can’t deliver. It also should avoid legal jargon.” By listing these, you guide the model to self-censor or adjust its wording. These are like mini content policies you’re embedding in the prompt. Models like ChatGPT have an internal content filter and style preferences, but giving your own custom ones can tailor the output.
Another example: For translation tasks, sometimes you want the translation in a particular reading level or maintaining certain terms. You could say, “Translate this document to Spanish, but preserve any technical terms in English and use formal address.” That mixes multiple constraints. The model is usually capable of juggling several conditions if they’re explicitly stated.
In essence, constraint-driven prompting is about reducing degrees of freedom in the output where necessary. This can be critical in business settings where consistency and compliance matter more than free-form creativity.
A note of caution: If you impose too many or contradictory constraints, the model may get confused or default to a generic response. Try to be concise and logical with constraints. If needed, test and refine (e.g., if it ignored a rule, consider rephrasing or highlighting it more, like “DO NOT do X”).
One more advanced idea: “Refusal or safe completions” – If you want the model to not talk about something, you can preface with something akin to the model’s own safety training: “If asked about proprietary algorithm details, respond with ‘I’m sorry, I can’t discuss that.’” This way, if your conversation might veer there (like you plan to paste some sensitive info), the model has a rule. This isn’t foolproof, but it shows how you can simulate a bit of guardrailing via prompt.
To conclude on this: Use guided prompts to shape the output to your needs. This can save significant editing time. For example, if you need a summary in bullet points, just prompt for bullet points (and maybe an example bullet to show style). If you need a polite decline email, list the messages it should contain (apology, cannot comply, perhaps an alternative solution). You essentially specify the components, and the model fills in eloquent language between those guardrails.
4.4 Iterative Refinement and Prompt Chaining
Not every task will be done in one prompt – sometimes you achieve better results by splitting the work across multiple prompts in a sequence, using the model’s output from one step as input to the next. We’ve hinted at this before (in CoT or Socratic methods, we simulate multi-step in one prompt), but here we talk about explicitly doing it in iterations. This approach treats the model like a collaborator that you repeatedly refine an answer with.
Iterative refinement means you get an initial answer, then you prompt the model further to improve or adjust that answer, possibly multiple times. This is natural in a chat setting: “Thanks for the draft. Now make it more concise and in a friendly tone.” Then, “Good, now add a short conclusion at the end.” You are steering the output closer to what you want over several turns. This is often more effective than trying to pack every requirement into one huge prompt at the beginning.
Sometimes you might even ask the model to critique or score its previous answer before refining. For instance: “On a scale of 1-10, how well did this answer address the question? If <8, revise it to better address any gaps.” Surprisingly, models can do some self-evaluation like this (though it’s not always accurate, it’s interesting).
Prompt chaining is a more automated concept where the result of one prompt is fed into the next prompt automatically. If you’re not using code or an orchestrator, you can still do this manually. For example, a workflow for writing an article might be:
Prompt 1: “Generate an outline for an article about XYZ.” (Model gives outline.)
Prompt 2: “Great. Now write the introduction section based on this outline: [paste outline part for intro].”
Prompt 3: “Now write section 2, which is [section heading]”. ... and so on, then
Prompt N: “Write a conclusion that ties together all the points. The key takeaways to emphasize are A, B, C.”You’re using each prompt to build a piece of the final result. This is similar to how one might logically break tasks when writing manually. The benefit is more control – you ensure each part is done well before moving on.
Another form of chaining is using one prompt to generate data for another. For example, “List the top 5 challenges in the industry.” Then take that list and prompt, “For each of these challenges, suggest a solution.” The final output is richer (5 challenges with solutions) because you structured it in two steps.
When to use iterative approaches:
- If the task is complex or lengthy (writing a long report, performing a detailed analysis), it’s often better to incrementally prompt rather than one giant prompt. This keeps the model focused and not losing track (long responses can get weaker toward the end as the model may lose some coherence).
- If the first output isn’t satisfactory, instead of regenerating from scratch, guide the model on what to fix. It already has a context of what it wrote.
- If you want multiple passes on the content: e.g., first get all ideas out (even if messy), then refine style and structure. Much like a human would do a rough draft then editing pass.
One creative strategy is “role shift” in iterative refinement: first the model writes something, then you say, “Now you are an editor, find ways to improve the above.” The model might produce suggestions or even mark up the text. Then you can ask it to apply those improvements. You can even iterate: “Now as a fact-checker, check the above.” This is like cycling the model through different hats to polish the content.
In professional settings, iterative prompting is realistic – rarely do we accept the first draft of anything. Using the AI in loops can get you to a final product that meets criteria more reliably. It’s essentially mirroring the edit-review cycle with the AI acting as both writer and (to some extent) reviewer.
There is some evidence that iterative prompting can reduce hallucinations or errors, because you have the chance to correct course. For example, if the initial answer had an incorrect fact, you can say, “Check the second paragraph for factual accuracy with source X,” if you have data to cross-verify.
Of course, iterative use of AI takes more time (and possibly more cost if via API) than a single prompt. So, weigh that. But for important outputs, it’s worth the investment.
Tip: Save important intermediate outputs (like that outline or list of points) either externally or in the chat, so you can refer back. In a long chat, the model has a memory window of recent content (few thousand tokens). If you go on too long, it might forget the very early parts. In those cases, re-paste the outline or key points as needed to remind it.
In conclusion, iterative refinement and chaining embrace the idea that prompt engineering can be a process, not just one shot. You guide the model through a workflow, much like supervising an employee through a task step by step. It allows error correction, addition of newly remembered requirements, and generally yields a more polished result. Don’t hesitate to use the AI as a partner that you can repeatedly query and instruct – it doesn’t get impatient!
4.5 Knowledge-Augmented Prompts (Retrieval Integration)
One of the most valuable uses of LLMs in business is to have them work with proprietary or domain-specific information – things the base model might not know. Since the model’s knowledge cutoff might be outdated or it may not contain, say, your internal company data, a knowledge-augmented prompt is a way to feed relevant information into the model so it can give grounded answers. This can be thought of as a manual (or sometimes automated) form of Retrieval-Augmented Generation (RAG), where you retrieve relevant text and prepend it to the prompt (arxiv.org, arxiv.org).
There are a few scenarios:
- You have a document or knowledge base, and you want the LLM to answer questions about it or summarize it.
- You have data (like a table of numbers, or logs, or code) and you want analysis or explanation.
- You want the model to stay factual by giving it sources to use.
How to do it: The straightforward way is to insert the information into the prompt with a clear boundary. For example:
[Background Information]
Acme Corp Q3 Report Excerpts:
* Revenue: $5M, which is 20% lower than Q2.
* Customer churn increased by 5%.
* … (a few key points)
[Task]
Given the above report, write a brief for the executive team highlighting the main issues and possible reasons.By structuring the prompt with a section containing the info (here labeled as background) and then the task, you’re giving the model explicit knowledge to use. It will very likely draw from those bullet points in its output. The important thing is to only include as much as needed (due to token limits and relevance) and to clearly delineate it so the model knows that’s reference material. Using quotes or a divider line can help.
This is effectively turning the model into a query engine over your provided data. It dramatically improves factual accuracy because the model can quote the given info rather than recall from training (which might be wrong or stale). Research indicates that having a retrieval step to provide relevant text can reduce hallucinations and improve performance on knowledge tasks (promptingguide.ai, arxiv.org).
For example, say you’re working on a legal brief. You could paste the relevant law excerpt and then ask the model to analyze how it applies to your case. The model will then focus on that text. Without it, the model might try to remember law (risky and often incorrect if specifics matter).
Another use: If you have a long text, you might chunk it and use multiple prompts – e.g., first summarize each part (prompt chunk by chunk), then ask for an overall summary. That’s a form of knowledge augmentation by breaking a large input into manageable pieces (since models have a context limit, often around 4k to 8k tokens for standard GPT-4, maybe more for 32k version, but still limited).
Automated variant: In some workflows, you could have a system (or manually) search a knowledge base for the top relevant documents given a question, then feed those docs into the prompt. This is what some enterprise chatbots do: user question -> search internal docs -> put top passages + question into GPT. The result is a highly accurate answer with references. If doing manually, you can do the search yourself and copy in what you find.
Important: When giving the model reference text, you may also instruct it to only use that text. For example: “Use only the above information to answer. If the answer isn’t in the information, say ‘I don’t have that info.’” This prevents the model from straying. It aligns with our earlier mention of constraints. It makes the model act more like an extractive QA system rather than generative (which is what you want if accuracy is paramount).
Another knowledge augmentation approach is embedding domain knowledge in the prompt implicitly via examples or roles. For example, if an LLM isn’t great at a particular niche, providing a few Q&A examples in that niche in the prompt can teach it those facts just-in-time. But the easiest is usually to just provide the relevant text.
Example use case: For an NGO writing a grant proposal, you could feed the model with a section of the call for proposals (the criteria, etc.) and ask it to draft the proposal emphasizing how your project meets each criterion. The model will use the language of the criteria in the draft, making it more aligned to what funders look for.
Another example: If you want an analysis of data, you might format the data in a readable way (maybe CSV snippet or list) and then prompt, “Given the above data, what trends do you see?”. The model can parse small tables or lists and offer insights (though caution: it’s not a spreadsheet, complex calculations or huge data are not its forte; but summarizing patterns from a page of data is doable).
In summary, knowledge-augmented prompting is about giving the model grounding information. It is one of the most high-impact techniques for business use because it lets the model speak to your specific situation, not just generic training data. It’s essentially how you give the model a short-term memory of facts you need. Many industry solutions are built around this concept (fetch relevant text then use LLM). For an individual user, it can be as simple as copy-pasting the relevant excerpt or facts before your question.
The upside is clear: better accuracy and relevance. The downside is you have to have or find that information. It also can make prompts long. But as long as it’s within limits, the model can handle surprisingly large context (thousands of words). Newer models with 16k or 32k token contexts can take in even more (like whole PDF chapters) – which blurs the line between “knowledge in prompt” and “knowledge in model.” But until models can know your data out of the box, augmenting via prompts is a powerful workaround.
These creative methods (4.1 to 4.5) show how you can push prompt engineering beyond basics to tackle complex, realistic tasks. By engaging the model from multiple angles, enforcing guidelines, refining iteratively, or feeding it data, you can extract more business value – whether that’s more insight, more accuracy, or simply saving more time. They are called “creative” or “speculative” because many of these ideas are still being explored and aren’t guaranteed to work in all cases, but they offer avenues for experimentation. You might find certain combinations of these that work best for your use cases. For instance, a multi-perspective analysis (4.1) combined with knowledge augmentation (4.5) – having the model take on different roles while referencing actual data, could yield a very rich report.
Next, we’ll explore how prompt engineering can be applied across various industries and tasks in a general way, and then we’ll focus on a special section for NGOs. This will ground these techniques in real-world contexts and show frameworks you can reuse.
5. Cross-Industry Use Cases & Frameworks
Large language models have broad applicability across industries and job functions. In this section, we’ll discuss how prompt engineering techniques can be applied to common categories of knowledge work: productivity, decision-making, communication, research, and analysis. Instead of focusing on any one industry (like finance vs. healthcare), we’re grouping by type of task, since many tasks (summarizing, planning, etc.) occur in multiple fields. For each category, we’ll illustrate use cases and outline prompting approaches or frameworks that can be generalized. The idea is to provide templates of thinking that you can adapt to your specific domain.
5.1 Productivity and Personal Efficiency
Use Case: Task Automation and Drafting. One of the most immediate benefits of ChatGPT and similar models is accelerating routine tasks. This includes drafting emails, writing documentation, creating meeting agendas, to-do lists, and more. Essentially, it’s using the AI as a first-pass generator or assistant for everyday work items.
For example, an information worker can prompt: “Draft a polite email to the IT department requesting a new laptop, mentioning that my current one is 5 years old and listing any company policies about equipment upgrades.” The model will produce a nicely worded email that you might only need to tweak a little (maybe adding the exact policy name if needed). That saves time compared to writing from scratch.
Prompting Framework: A general approach for productive drafting is to include in your prompt:
- The type of output (email, report, code snippet, outline, etc.)
- The key content points to include (the facts or requests).
- The tone/style if important (e.g., formal, friendly, concise).
- Any constraints (like length or things to avoid).
So a template could be: “Write a [tone] [format] about [key content]. It should include [A], mention [B], and remain under [X words/paragraphs].” For instance, “Write a concise update (one paragraph) to the team about project Alpha. It should include the latest status (we finished phase 1), the next steps (testing), and thank them for their work. Use a positive, motivating tone.” This prompt is quite specific, and the output will likely be ready to send or paste into a chat with minimal changes.
Use Case: Summarization for quick digestion. Another big productivity boost is summarizing long materials. You might not have time to read a 10-page report, but you can prompt an LLM: “Summarize the attached report focusing on the main recommendations and any data mentioned.” If you can feed the text (some chats allow uploading, otherwise copy-paste if short enough or break it up), the model will give you a succinct summary. People use this for articles, transcripts of meetings, lengthy emails, etc. Summarization prompts can be tailored: “in 5 bullet points”, or “for a beginner audience”, etc. If you have multiple documents, you can summarize each then ask the model to synthesize (iterative approach from section 4.4).
Framework: Progressive Summarization. One general method: if text is very long, do chunked summarization: “Summarize the following text…” for each chunk, then combine those: “Summaries: [list]. Write an overall summary.” This is a bit mechanical but effective for huge inputs. There are also tools that do this automatically with LLMs in the backend.
Use Case: Brainstorming and Creativity. Productivity isn’t just about routine tasks – it’s also about coming up with ideas quickly. LLMs can act as brainstorming partners. For example, “List 10 ideas for social media posts promoting our new product” or “Brainstorm possible themes for this year’s annual conference, related to innovation in healthcare.” The key in prompting here is to set context (what you’re ideating on) and possibly ask for variety: “Give diverse ideas” or “out-of-the-box” if you want creativity. The model can generate ideas that you might refine or combine. You can then take each idea and prompt further: “Expand on idea #3.” This helps turn a rough idea into a more fleshed-out concept.
Framework: IDEA generation. You can use a prompt template: “Generate [N] ideas for [problem/task], including at least one that is [constraint].” For instance, “Generate 5 ideas for reducing meeting times, including at least one unconventional idea.” This nudge yields a varied list by design. Another trick: explicitly ask for categories of ideas: “Give me some ideas from a cost-saving perspective, and some from a employee-morale perspective.” That’s combining multi-perspective (section 4.1) with brainstorming.
Overall, in productivity tasks, prompt engineering is often about being specific with context and desired outcome. General requests (“Do my work for me!”) won’t yield useful output. But targeted ones (“Draft X with Y points”) will. Workers have found that even if an AI draft is only 70% good, that last 30% editing is much faster than starting at 0%. And as per the MIT study we cited, quality often goes up too (news.mit.edu).
5.2 Decision-Making Support
When facing a decision – whether it’s a business strategy, an investment, or even a personal career decision – LLMs can help structure the problem and lay out considerations. It’s important to note: the AI should not be the decision-maker, but it can function as an analyst or sounding board to support your decision-making.
Use Case: Pros and Cons Analysis. A classic approach: “What are the pros and cons of doing X?” The model will typically give a balanced list. To prompt well, you might specify context: “Pros and cons of adopting a remote work policy for a mid-size tech company.” You can also ask it to emphasize certain types of pros/cons (financial vs. cultural, etc.). This output serves as a checklist of points that you can verify or consider further. It might bring up a con you hadn’t thought of, for example, “potential impact on mentorship and training of new employees”. This can augment your own list.
Framework: SWOT or similar frameworks. You can directly prompt the model to fill in a framework from management. For instance: “Perform a quick SWOT analysis (Strengths, Weaknesses, Opportunities, Threats) for our plan to expand into online retail.” The model knows what a SWOT is (wholewhale.com) and will likely produce a structured answer with each category. It might identify, say, Strength: strong brand, Weakness: limited e-commerce experience, etc. You, as the user, would then examine if those ring true or if something’s missing. This saves time of manually brainstorming each quadrant from scratch.
Similarly, you could do a PESTLE analysis (Political, Economic, Social, Technological, Legal, Environmental factors) or Porter’s Five Forces, etc., by prompting the model accordingly. It has knowledge of these business analysis frameworks and can populate them with relevant points. Of course, you’ll refine them based on actual data of your situation, but it gives a solid starting template.
Use Case: Scenario simulation. Decision-making often involves “What if…?” scenarios. You can ask the model to simulate outcomes: “Imagine we increase the price by 10%. What might happen in terms of sales volume, customer perception, and competitor reactions?” The model will outline a plausible scenario (e.g., sales might drop some, profit per unit up, maybe customers react with some complaints, competitors might or might not follow pricing, etc.). This is valuable to prompt you to consider the ripple effects of a decision. You might run multiple scenarios: “What if we lower price by 10%?” or “What if a new competitor enters?” and compare.
Use Case: Policy or Document drafting to support decisions. Often making a decision also means creating a proposal or policy document. Using prompts to generate those drafts can help clarify the decision. For instance: “Draft a one-page decision memo recommending whether to outsource our customer support or keep it in-house. Include background, options considered, recommendation, and rationale.” This will produce a structured memo that you can then customize with actual data or preferences. Importantly, by writing out a recommendation (even hypothetically), you might see the logic gaps or arguments needed, which then informs your actual thinking.
Use Case: Risk analysis and mitigation. For any decision, asking “What could go wrong and how to mitigate it?” is wise. You can prompt: “List potential risks of launching this product by Q4, and suggest a mitigation for each risk.” The output might say: risk – not enough time to test quality (mitigation: allocate extra QA resources or a soft launch), risk – competitor reaction (mitigation: emphasize our unique features, lock in key customers early), etc. This is similar to pros/cons but specifically focuses on downsides and how to handle them, which is gold for decision prep.
In all these cases, the model provides structured thinking. It’s like having a junior analyst who drafts a report – you still have to validate and adjust it with real knowledge, but it saves you from staring at a blank page or forgetting a category of concern. McKinsey research suggests AI can boost decision-making processes by quickly synthesizing information and options (mckinsey.com).
One must be careful though: LLMs do not truly know your business specifics. So, any analytic output should be reviewed. But as a starting point, it’s often quite reasonable (it draws from general business knowledge and analogous situations it has read about).
A tip: if the decision involves numbers or data analysis, be cautious. Models are known to sometimes fudge math or assume data. It may say “sales will drop 5%” without basis. Use it to list factors, but rely on actual data for quantitative estimates. Or ask it to outline how to calculate something rather than giving the final number (e.g., “How would one estimate the ROI of X? What factors to consider?”).
By using prompts in decision support, you ensure you’re asking relevant questions and considering multiple facets. It can make your decision process more robust and faster, but always keep you (and any human experts) in the driver’s seat for the final call.
5.3 Communication and Content Creation
Communication is a broad area that spans writing, editing, translating, and tailoring messages to different audiences. Prompt engineering can assist in all these facets, ensuring clarity and effectiveness of communication in a business or general context.
Use Case: Email and Letter Writing. Emails are the lifeblood of office communication. We’ve mentioned drafting emails in productivity, but let’s elaborate. For tricky communications – say a delicate customer issue or a resignation letter – a well-crafted prompt can produce a strong draft. Example: “Write a professional email to a client, apologizing for a delivery delay on their order, explaining the reason (unexpected supply issue) and offering a 15% discount on their next purchase.” The output will likely hit the right notes: apology, brief explanation, remedy, and a courteous tone. This saves time and also might phrase things in a polished manner. Always review to ensure it aligns exactly with your situation (e.g., reason given is accurate, etc.).
If the first draft isn’t perfect, you can iteratively refine tone: “Make it sound more empathetic” or “shorten it to three sentences.” This interplay uses earlier principles.
Framework: The 3C’s (Clear, Concise, Courteous) – instruct the model. For professional comms, I often say in the prompt “Use clear and concise language” as an extra nudge, which ChatGPT already tends to do, but it ensures no overly flowery or rambling output.
Use Case: Report Writing and Formatting. For longer communications like reports, proposals, or press releases, LLMs can help with structure and even content for boilerplate sections. For instance: “Create an outline for a quarterly marketing report, including sections for performance metrics, highlights, challenges, and next quarter plan.” Then, you could take each section and prompt further (“Draft the introduction section: …”). While the model may not know your metrics, it can craft generic sentences where you fill numbers in: e.g., “Our campaign reach increased significantly, with over [X]% growth compared to the previous quarter.” You insert X. This is like having a template with nice wording ready.
For formatting, you might ask: “Provide the output in Markdown with bullet points for each key point.” If you plan to move to a specific format (PowerPoint, etc.), you can ask for a structure like “List key message for each slide (1 through 5).” This helps plan communication pieces.
Use Case: Tone Transformation. Perhaps you have content and you need it in a different tone or reading level. Prompt engineering shines here. “Rewrite the following paragraph in a more friendly and simple tone for a public blog post.” or “Translate this technical explanation into layman’s terms.” The model will adjust word choice and sentence structure. This is useful if you have something like a legal statement and need a plain language version. Or conversely, you wrote a casual note and need it more formal. You can feed the text and say “make it formal.”
Use Case: Multilingual Communication. If you work across languages, prompts for translation or bilingual content are extremely handy. For example: “Translate the following customer feedback from Spanish to English, and then draft a reply in Spanish acknowledging their concern.” In one go, you get the translation plus a reply in the original language. Or, “Provide an English summary of this French document.” LLMs like GPT-4 are quite proficient at translation and summarization combined (wholewhale.com). Still, for official translations, it’s good to have a human review, but this speeds up first passes or internal understanding. A nuance: you can instruct about preserving certain terms or tone in translation (as mentioned earlier).
Use Case: Social Media and Marketing Content. Communication externally often means catchy, brief content. Prompts can be: “Draft three Twitter posts (under 280 chars each) announcing our new product launch, with an excited tone and including the hashtag #NewAtAcme.” The model will produce some options. You can also do variations: “One of the tweets should contain a question to engage audience.” Or “Write a LinkedIn post (~150 words) giving a thought leadership take on [topic], and end with a question to encourage comments.” The adaptability here is great – you can generate multiple versions, then pick or tweak your favorite. Marketing and PR folks often need to adapt one message to multiple platforms; you can prompt those specifically (Twitter vs LinkedIn vs email announcement all have different style needs).
Framework: AIDA for marketing copy. The AIDA (Attention, Interest, Desire, Action) model is a common formula. You can prompt the model to use it: “Write a promotional email using AIDA framework to encourage sign-ups for our webinar on AI in finance.” It might output with sections or at least implicitly follow the flow: a catchy opening (Attention), info that generates interest, reasons to desire (benefits of attending), and a call-to-action (sign up link). Similarly, “Before-after-bridge” or other copywriting formulas can be prompted if you mention them.
Use Case: Internal communications & policies. LLMs can help draft things like company announcements or first drafts of policies (which then legal or HR reviews). For example: “Draft a company-wide announcement about our new flexible work hours policy, explaining how it works and why we’re doing it, in a positive tone.” The model will compose a fairly comprehensive announcement hitting those points. You might need to insert some specifics (like exact hours or date effective), but the framing and wording (like expressing commitment to work-life balance) it will handle (mckinsey.com).
Use Case: Editing and Proofreading. If you have something written but want to check it, you can prompt the model: “Proofread the following for grammar and clarity.” It will output a corrected version. Or “Find any overly long sentences in the following and split them or simplify them.” Essentially, the model can act as a writing assistant to refine existing text, not just generate new text.
One could worry about tone: There was an interesting anecdote from a McKinsey explainer which compared two prompts (one generic, one more specific) to show how being specific yields more targeted info (mckinsey.com). Similarly in writing, a prompt with specifics yields better content. Always mention the key points you want included, so the model doesn’t forget them.
By leveraging prompt engineering in communication tasks, you can ensure clarity, consistency, and save a lot of time. A colleague of mine refers to ChatGPT as a “universal writing intern” – it can draft anything from a blog post to a formal letter quickly. The human’s job becomes reviewing and fine-tuning the content, which is much faster than composing the whole thing. It’s also useful for people who might not feel very confident in writing; an AI draft can overcome writer’s block or uncertainty.
One should be mindful of confidentiality – don’t paste sensitive info into a public model prompt (unless using a self-hosted or privacy-guaranteed service). But for general communication content, it’s a game changer in productivity.
5.4 Research and Knowledge Management
In research-oriented tasks – whether academic, scientific, or market research – prompt engineering can assist with gathering, synthesizing, and analyzing information. LLMs can’t go fetch new info from the web in real-time (unless augmented with tools), but they are trained on a lot of knowledge and can help summarize what’s known, generate hypotheses, or analyze text and data you provide.
Use Case: Literature Review Summary. If you are exploring a new topic, you can use LLMs to get an overview. For example: “Explain the concept of ‘digital twin’ technology and summarize current trends or recent developments, as of 2023.” The model will produce a synthesized answer from what it “knows”(news.mit.edu). It might mention definitions, some applications, maybe mention if it read about some recent uses (though be cautious about post-2021 knowledge if using a model with that cutoff; GPT-4 has some 2021 knowledge; however GPT-4 has seen internet data up to 2021 and some beyond depending on training). This is a quick way to educate yourself on a topic, almost like a custom Wikipedia entry.
For deeper research, you might prompt it with content from papers. For instance, take an abstract of a paper and ask: “Summarize the key findings of this study and what gap in knowledge it addresses.” Or “Compare the findings of Study A (given summary) with Study B (given summary).” The model can highlight similarities or differences.
Use Case: Extracting Information. If you have a large piece of text (like a legal contract, a transcript, or a scientific paper), you can use prompts to extract specific info. E.g., “From the following transcript, list all the commitments made by person X.” or “Read this article and pull out the statistics and their context.” The model will scan the text and present the info in the form requested. This is essentially question answering based on text you supply, making it a powerful knowledge management tool. It’s like an intelligent search within documents.
Framework: For extraction, you can say “List all X from Y” or “Does Y mention Z? If so, what does it say?” Very direct queries work well. LLMs are decent at semantic understanding, so they might find relevant parts even if wording differs.
Use Case: Data Interpretation. Suppose you have some data (maybe the output of a survey or analytics). While caution is needed, you can ask: “Here are results from a survey (paste). What are the main themes people mentioned as positives and negatives?” The model will try to categorize free-form responses into themes. This is qualitative analysis assistance. It might say, e.g., “Positive themes: friendly staff, flexible hours. Negative themes: workload, communication issues.” This can jump-start your analysis, which you then verify.
If you have a spreadsheet exported as CSV text, you can prompt like: “Given the following data, summarize any trends: [paste CSV rows].” The model may mention, for instance, “Sales increased each month, with a peak in July, then slightly declined.” It can handle basic pattern recognition. But double-check any numeric claims – it might miscalculate exact figures.
Use Case: Hypothesis Generation and Testing. For researchers or analysts, sometimes you want to explore hypotheses. You can have an LLM generate some. “What are some possible explanations for [phenomenon]?” It will list hypotheses. Or “Suggest an experiment to test if [A causes B].” The model, being versed in scientific method broadly, might propose an experimental setup. It’s like a brainstorming partner with a lot of textbook knowledge.
Also, for analysis, you might do: “Here is some background. What further data would you want to collect to confirm [hypothesis]?” The model might enumerate data points or methods, which is useful to sanity-check your research plan.
Use Case: Knowledge Base Q&A. If you have an internal knowledge base or some large document (like an employee handbook, or a product manual), you can use LLM prompting to query it. For example, “According to the handbook (text given), what is the policy on parental leave?” It will extract the answer. In a sense, you can create a mini QA system for any text by just feeding that text along with a question. This is extremely useful for knowledge management – it’s like having an AI that instantly reads documents for you and tells you what you need to know (ccsfundraising.com).
Use Case: Reference and Citation Assistance. While you should not trust an AI to give you correct citations (they often fabricate references), you can prompt it to provide context or related works. E.g., “What are some notable research studies on the effects of remote work on productivity? Just give names of authors or years if known.” It might list a couple of well-known studies if it recall them (like a Stanford study or something). Then you can follow up on those manually. It’s hit-or-miss, but sometimes it does recall actual references (ar5iv.org). Always verify, as AI can name things that sound plausible but aren’t real (known as “hallucinated references”).
Use Case: Operational Research – Querying Logs or Code. If you’re a tech worker, you might even use ChatGPT to interpret code or logs. For example, “This error log [paste]; what might be the cause?” The model might recognize patterns in the error and suggest a cause or next step. Or “Explain what this code function does.” It will do a line-by-line explanation in plain English. This is a form of knowledge management for technical knowledge (the “knowledge” being code semantics). While not foolproof, it’s often accurate and can save time reading someone else’s code or legacy code.
Caution in Research Use: LLMs can sound confident but be wrong. They aren’t connected to a database of up-to-date verified facts unless you provide it. So in any serious research scenario, use them for summarization and hypothesis, but cross-verify factual claims from trusted sources. When we said it can act like a custom Wikipedia, remember Wikipedia itself is a tertiary source that needs checking against primary ones.
For knowledge management tasks, it helps to clearly separate what information you are providing vs what you want from it (so the model doesn’t mix its own knowledge incorrectly). Using quotes or a delimiter for provided text is good. Also, if you suspect the model might guess incorrectly, explicitly instruct, “If the answer is not directly stated, say you cannot find it.” This can reduce hallucination (though it might still guess; GPT-4 is better at saying when it’s unsure, but not perfect).
In summary, prompt engineering in research contexts is about asking the right questions and feeding the right information to get meaningful, synthesized answers. It accelerates getting up to speed on new topics and extracting insights from large text corpora. It is like an assistant who can rapidly read and summarize or compare notes across many documents, albeit with the need for oversight by an expert (you).
5.5 Data Analysis and Insights
While LLMs are not spreadsheets or databases, they can complement data analysis by explaining data, finding patterns in data descriptions, generating code for data analysis, or even acting as a pseudo-analyst interpreting results. This crosses into the territory of using specialized tools (like Python with pandas, etc.), but focusing purely on prompt-level, here are some ways they help in analysis:
Use Case: Explaining Data Findings. If you have results from an analysis that you want to communicate, you can prompt an LLM to phrase it well. E.g., “Explain in plain language what it means that ‘conversion rate increased from 2% to 3%’ and why that might be important.” The model will produce a reader-friendly explanation (like “The conversion rate went up from 2 to 3 out of 100, which is a 50% increase. This means more visitors are doing the desired action, which is a positive sign; it might be due to our recent website improvements…”). This helps to turn dry numbers into meaningful narrative.
Use Case: Suggesting Analytical Approaches. If you’re stuck on how to analyze a dataset, you can describe it and ask: “What analyses or visualizations would you suggest for this dataset which has columns A, B, C…?” The model might suggest, for example, “Plot A over time to see trend, do a correlation between A and B to test relationship, segment by category C to see differences.” This is similar to having a brainstorming session on analytic methods.
If you have a hypothesis, you can ask how to test it: “I suspect that user engagement is higher on weekends. How could I verify that with data?” The model might suggest comparing average engagement metrics for weekends vs weekdays and running a statistical test. It’s not doing the test, but it guides you how to.
Use Case: Formula or Code Generation. If analysis requires writing formulas or code (e.g., Excel formulas, SQL queries, Python code), an LLM can often generate them correctly from natural language. For instance: “Write an Excel formula to calculate the compound annual growth rate (CAGR) given a starting value in cell B2, ending value in C2, and number of years in D2.” The model could output something like =(C2/B2)^(1/D2)-1. You double-check it, but likely correct (wholewhale.com). Or “Give me a SQL query to find the top 5 customers by revenue from a sales table with fields (customer_id, amount).” It’ll produce a SQL snippet with GROUP BY and ORDER BY.
For Python, you could say “Show Python code using pandas to read a CSV and calculate summary statistics for each column.” It will write a code block. This is tremendously useful if you’re not an expert coder – you get a scaffold you can use. (Note: In ChatGPT interface you can even have it refine code if there’s an error, etc. In pure prompt context, you just get the code then test it outside.)
Use Case: Interpreting Statistical Results. If you have outputs like “p-value = 0.03” or a regression result, you can ask the model to interpret: “We ran an A/B test and got p = 0.03. Explain what this means about the significance of results to a non-technical stakeholder.” It will likely say something about there’s a 3% chance the difference is due to random chance, so results are considered statistically significant, meaning variant B likely really outperformed A, etc., in plain terms. This saves time turning stats into narrative.
Use Case: Anomaly Detection Brainstorm. If you see a weird data point or trend, you can ask the model: “Our website traffic spiked 50% on a single day, what could be possible reasons?” It might list: media mention, bot traffic, a glitch in analytics, a one-time event, etc. Good analysts would think of these, but the AI can ensure you don’t miss obvious ones. Then you investigate each possibility.
Use Case: Converting Units or Formats. Sometimes analysis involves fiddling with units or formats. A quick prompt like “Convert the following list of temperatures from Celsius to Fahrenheit: 20, 35, 50.” The model should output the converted values. Or “sort this list of numbers” etc. Basic but handy if you don’t want to open a spreadsheet (though be mindful to verify – small calculations it usually does fine).
In essence, for analysis tasks, LLMs:
- Provide explanations (of data, results, methods).
- Suggest methods (analysis approaches, tests, visualizations).
- Write or assist with analytical tools (formulas, code).
- Help in interpreting outputs for communication.
They won’t replace actual data processing (you still need to run calculations, use actual data tools for large datasets), but they act as a very knowledgeable assistant in analysis. It’s like having a tutor or collaborator who knows statistics and programming to bounce things off.
One framework: “Insight, Implication, Action” – when analyzing, you could prompt the AI to structure findings that way. For example: “Here is the analytical result: [X]. Provide an insight from it, the implication of that insight, and a recommended action.” The model might say: Insight – sales highest in region A. Implication – maybe marketing campaign was effective there or that region has most demand. Action – consider focusing efforts or investigating what drove region A’s success and replicate elsewhere. This helps translate raw analysis into business next steps.
Finally, across these use cases, we see that prompt engineering simply helps to ask the right question of the model for the task at hand. Each industry or role might have its own lingo or common tasks, but the patterns of prompting remain similar: giving context, specifying format, and guiding the style of output.
Next, we’ll focus on a particular sector – NGOs – to illustrate applying prompt engineering in a domain with specific needs (fundraising, policy, etc.), and then we’ll wrap up with tooling and future trends.
6. Prompt Engineering for NGOs
Non-Governmental Organizations (NGOs) and non-profits have unique communication and operational needs. They work on fundraising, advocacy, policy drafting, volunteer coordination, and more – often with limited resources. Prompt engineering can be a force multiplier for NGOs, helping draft compelling narratives, streamline policy documents, and generate communications that further their mission. Let’s explore some NGO-specific applications, aligning with tasks like fundraising, policy writing, advocacy, and operational efficiency.
(Even if you’re not in the non-profit sector, many of these use cases parallel those in other fields – e.g., fundraising letters vs marketing emails, policy briefs vs business memos – so the techniques are transferable.)
6.1 Fundraising and Donor Outreach
Use Case: Donation Appeal Letters/Emails. Crafting a persuasive appeal for donations is a critical task for NGOs. You want to connect emotionally with donors, explain what their money will do, and prompt action. A prompt to help with this might be: “Write a heartfelt fundraising email for our animal shelter. Mention a success story of a rescued dog (for emotional connection), emphasize that donations will help build new kennels, and include a call-to-action to donate via our website.”
The model will likely produce a structured email: it might start with a story of a particular dog’s rescue and recovery, then segue into how the shelter needs support to help more animals, then directly ask for a donation. It will use emotive language (because we said “heartfelt”) and specificity (as we gave specifics like building kennels) (mckinsey.com). NGOs can reuse these outputs almost as-is, perhaps plugging in a real name for the dog story and the donation link. It saves time and can increase quality of appeals.
If you want multiple versions or to A/B test, you can ask “Give me two alternate versions with different subject lines.” The AI might produce one with subject “Help us build new kennels for dogs like Buddy” and another “Your compassion can give stray dogs a home.” These can be tested with donors for effectiveness.
Use Case: Grant Proposal Writing. Grants often require detailed proposals that align with funders’ guidelines and language. ChatGPT can aid by organizing and formalizing your content. For example, after you gather info for each section of a grant (need statement, project description, outcomes, budget justification), you can prompt for each section: “Draft the Need Statement: emphasize the lack of healthcare access in the community and use data X, Y.” The model will produce a coherent paragraph or two integrating that data into a compelling narrative of need. It acts like a grant writing assistant, ensuring professional tone and clarity, possibly even catching logical flow issues (like making sure the need leads to the proposed solution).
You can also ask the model to review and refine text: “Here is a rough draft of our project outcome section. Improve its clarity and persuasiveness.” It will edit it, perhaps making the connection between activities and outcomes more explicit or using more affirmative language like “will achieve” vs “hopes to achieve”.
There’s caution that factual claims in proposals must be accurate – the model might inadvertently embellish if not guided. Always check against your actual data. But it’s very useful for phrasing and structure.
Use Case: Donor Acknowledgements. Thanking donors promptly and warmly is key. You can automate drafts of thank-you letters: “Write a thank-you note to a donor who gave $500. Acknowledge their generosity and mention we reached our project goal of building a community well, which their support made possible.” The output will graciously thank the donor, possibly say how $500 makes a difference, and reinforce the impact (“because of you, 50 families now have clean water”). These letters strengthen donor relations. The AI ensures you hit the right appreciative tone every time without starting from scratch for each letter. Just adjust the specifics per donor or amount as needed.
In NGO comms, personalization is valued, so you might still add a line specific to that donor (if you know them), but the heavy lifting is done.
Use Case: Donor Reports. Many major donors or grants require reports on how funds were used. Prompts can help summarize outcomes and usage of funds in a clear way. For example: “Summarize in one page how the $50,000 grant from XYZ Foundation was utilized and what outcomes were achieved, using a positive and grateful tone.”
The model will lay out something like: “With the generous $50k grant from XYZ Foundation, our organization accomplished A, B, and C. Specifically, [some outputs]. This led to [outcomes]. We are deeply grateful for XYZ’s support in making this possible.” You obviously feed it the details (A, B, C), but it ensures the text flows and that gratitude is conveyed properly. It’s like having a report writer smoothing out your bullet points into polished prose.
One NGO-specific nuance: It can help avoid jargon when communicating to lay donors. You can instruct “Ensure it’s understandable to someone not familiar with technical terms.” The AI will simplify language (like “waterborne illness” instead of a complicated medical term, if needed, or at least explain it).
Framework/Tone: Nonprofit appeals often use the “story of one” technique (tell one beneficiary’s story to represent the broader issue)(ccsfundraising.com). You can prompt the model to incorporate that: “Include a brief story of a person who benefited.” And also use “you” focused language to engage donors (“Your donation did X”). If you include those pointers, the model will follow them in style. Actually, GPT often does that by default in fundraising appeals, but prompting makes sure.
Also, NGO communications are typically emotion + impact. So a simple formula: Hook with emotion (story or startling fact) -> explain need -> present solution -> ask for help (donation) -> promise of impact + thanks. You can tell the AI to use that flow: “Use an emotional hook, then explain the need, then the solution, then end with an appeal for help and a thank you.” It will structure accordingly.
6.2 Policy Writing and Analysis
NGOs frequently engage in policy work – whether it’s drafting policy recommendations, responding to government proposals, or writing position papers on issues. These documents need to be clear, well-argued, and often backed by evidence. Prompt engineering can aid at multiple stages: drafting, summarizing, and refining.
Use Case: Drafting Policy Briefs. Suppose an NGO advocates for environmental policy. They might need a 2-page brief for lawmakers about a proposed regulation. A prompt to help could be: “Draft a policy brief arguing in favor of renewable energy subsidies. Structure it with an introduction, background on current energy mix, benefits of subsidies (economic, environmental), counter-arguments and rebuttals, and a conclusion urging passage of subsidy legislation. Target the brief at policymakers, using a formal, evidence-driven tone.”
That’s a detailed prompt, but it results in the model writing a quite structured brief. It will follow the sections: intro (maybe citing need to meet climate targets), background (share of renewables etc.), benefits (jobs, emission cuts), counter-arguments (cost or market distortion concerns) with rebuttals (long-term benefits etc.), conclusion (urge action). The language will be formal and likely include some general stats or reasoning (mckinsey.com).
The NGO staff can then insert specific data or references where needed. The advantage is the model did the heavy lifting of structure and even phrasing common arguments, saving the team a lot of time. It’s like giving it the outline and it returns a full draft.
Use Case: Summarizing Legislation or Policies. NGOs often need to read through dense policy documents or laws and summarize them for their team or the public. For instance: “Summarize the key provisions of the Data Privacy Act 2024 and explain how it will affect small nonprofits in 3 paragraphs.” If you feed in the text of the act (or at least a summary of provisions from somewhere), the model can output a concise summary focusing on parts relevant to nonprofits (especially if in the prompt you say “affect small nonprofits”). It might say e.g., “It introduces requirements A, B, C. Nonprofits will need to do X. It may raise compliance costs but also protects beneficiary data etc.” Useful for quick comprehension and communication.
Even without feeding full text, ChatGPT has knowledge of many public laws (if they are pre-training, but careful: if it’s something very new, it might not know details unless a summary is in the corpus. If using an updated model or retrieval, better. Alternatively, paste any press release or analysis of the law and have it summarize that in lay terms.)
Use Case: Comparative Analysis. NGOs might compare policies from different regions or times. You can prompt: “Compare the climate change policies of the EU and the US in terms of renewable energy targets and carbon pricing.” The model will likely outline key differences and similarities (EU has Emissions Trading Scheme, US maybe lacks federal carbon price but has other initiatives, etc.). This can serve as a first draft of a comparative section in a report. Of course, verify specifics, but it’s often directionally correct, especially for well-known policy differences.
Use Case: Advocacy Messages to Policymakers. For advocacy, an NGO might send letters or briefing notes to officials. A prompt could help: “Write a one-page advocacy letter to the Minister of Health urging adoption of a harm reduction policy for drug use. Mention evidence from other countries that it saves lives and reduce costs. Use a respectful but firm tone.” The letter the AI drafts will include flattering acknowledgment of the minister’s efforts perhaps, then key arguments with maybe a reference to “In Portugal, for example, decriminalization led to lower overdose rates (ccsfundraising.com)” (it might know or generalize such evidence), and a concluding appeal to act. The NGO can then insert actual references or adjust nuance, but much of the framing is done.
Use Case: Policy Language Drafting. If an NGO needs to propose actual wording for a policy (like a proposed amendment or rule), LLMs can help with formal legal language. E.g., “Draft a clause for a city ordinance that prohibits single-use plastics in city facilities, including enforcement mechanism and effective date.” It might produce something legally worded like “Effective January 1, 2025, the use of single-use plastic products (including X, Y, Z) shall be prohibited in all facilities owned or operated by the city. Violations of this section shall be subject to [enforcement details]. The City Department of Sanitation shall be responsible for enforcement and may issue guidelines….” etc. Lawyers would refine it, but it’s a great starting template, making sure you didn’t forget effective date or enforcement.
Use Case: Internal Policy Documents. NGOs also have internal policies (HR, safeguarding, etc.). Drafting those can also use AI assistance, similar to corporate settings. The difference is maybe values language – NGOs often include mission or values in policies. You can prompt: “Draft an internal policy on social media use for our NGO staff. It should encourage respectful, inclusive communication online and remind staff not to speak on behalf of the org without permission. Tone should be positive and empowering rather than punitive.” The output will cover guidelines and likely phrase it like “We encourage you to use social media to share your passion, but remember… [guidelines]…” focusing on positive, as asked. That saves HR time writing from scratch and ensures alignment with the organization’s ethos (especially if you mention the values).
Note: In all policy-related outputs, verifying facts and ensuring alignment with the org’s stance is crucial. LLMs might introduce a generic argument that your org doesn’t emphasize, so editing for content is needed. But style and structure-wise, it’s a big help.
Also, citations: If a policy brief needs references, it’s best the NGO researcher insert them. The model might say “studies show X” generically. It’s up to you to replace that with a footnote to an actual study. One trick: if you know a stat but not exact wording, prompt the model: “Incorporate this statistic: ‘90% of our program graduates find jobs within 6 months’ into the argument about program effectiveness.” It’ll weave it in nicely.
6.3 Advocacy and Communications
Advocacy for NGOs involves educating the public, rallying support, and influencing opinions. It overlaps with some previous sections but let’s focus on public-facing comms specifically for advocacy: social media, campaign slogans, educational content, etc.
Use Case: Social Media Campaigns. Suppose an NGO is running an advocacy campaign (e.g., raise awareness about plastic pollution). They will need a series of social posts, slogans, possibly a hashtag, and content across platforms.
Prompts can generate a pool of creative assets:
- “Suggest 5 potential hashtags for a campaign encouraging recycling and reduction of plastic waste.” It might propose #PlasticFreeFuture, #ReduceReuseRecycle, etc. (You’d then check they aren’t widely used or have unintended meanings.)
- “Write a Twitter thread of 3 tweets that highlight the impact of plastic pollution on marine life, ending with a call to action to reduce plastic use.” The model will produce a mini thread, maybe: tweet1 about a turtle story, tweet2 with a stat (“8 million tons of plastic enter oceans annually”), tweet3: call to action and link. Very useful for busy comms managers to get content ideas.
- “Create a catchy slogan (max 8 words) for our anti-plastic campaign.” It could give something like “Sea life not plastic strife” or “Plastic is not fantastic”. Not all suggestions will be gold, but it’s brainstorming – you might refine or combine them.
Use Case: Press Releases. When an NGO does something newsworthy (launch a report, win an award, host an event), they need press releases. A prompt could be: “Draft a press release announcing that our NGO, CleanCoast, has partnered with the local government to launch a beach cleanup initiative. Include a quote from our director, Jane Doe, expressing enthusiasm, and a quote from the Mayor about community impact.” The output will have the press release format: location, date, announcement, a quote from Jane (the model will fabricate it but you’ll refine it to what she’d plausibly say), a quote from the Mayor (again you adjust content), background info on CleanCoast, and contact info line if you asked for it. Very close to usable format (mckinsey.com). You’d just tailor the quotes and ensure factual details are correct.
Use Case: Public Education Content. NGOs often publish explainers or Q&A to educate the public on issues (like a “What you need to know about climate change” factsheet). LLMs excel at turning technical info into lay-friendly text. For example: “Explain in simple terms how climate change leads to more extreme weather events, in one paragraph.” Great for FAQs or myth-busting content. Another: “Write a short explainer (200 words) on the importance of vaccination, addressing common concerns calmly and factually.” The model will produce a balanced explanation which can serve as a draft for an infographic or blog post. It tends to include analogies or simplified explanations which might work well.
Use Case: Volunteer Recruitment Messages. Advocacy isn’t just external – recruiting supporters and volunteers is key. A prompt like: “Write a motivational Facebook post recruiting volunteers for our upcoming river clean-up event. Emphasize that it’s fun, community-building, and makes a difference, and provide sign-up details.” The result: an upbeat post, perhaps starting with a question “Looking to make a difference in our community?”, then details of the event, a rallying line like “Join us in cleaning the river banks and enjoy a day of positive impact!” and then “Sign up here: [link]”. Saves the social media manager from having to come up with new enthusiastic wording each time.
Use Case: Storytelling for Advocacy. Perhaps you want to highlight a beneficiary story as part of a campaign (like how a scholarship changed someone’s life as part of an education advocacy campaign). If you provide the key points of the story, the AI can weave it into a compelling narrative. “Using the following facts, write a short story (~150 words) we can share in our newsletter: [facts about a student named Maria who, thanks to our scholarship, became the first in her family to attend college, overcame challenges, now giving back]. Make it inspirational and narrative in style.” It will likely produce a touching mini-story that engages readers emotionally, which is exactly what you want for advocacy donors or supporters.
Use Case: Multilingual Advocacy. If the NGO operates in multilingual contexts, they might need content in multiple languages. As mentioned earlier, the model can translate or even transcreate (adapt culturally). One could write an English version of a campaign message and prompt, “Translate and adapt this message for a Spanish-speaking audience in Mexico, ensuring cultural relevance and maintaining the persuasive tone.” The AI might adjust idioms or references accordingly (at least somewhat; always good to have a native speaker review if possible, but it gets you a long way).
One thing with advocacy communications is ensuring consistency in messaging across materials. If you use the AI, it may phrase a core message differently each time. It’s wise to identify your key messages and either include them verbatim in prompts or once you get a phrasing you like, reuse it. You can even instruct: “Use the phrase ‘healthy oceans, healthy communities’ as the tagline.” Then it will incorporate that motto everywhere.
6.4 Operational Efficiency
Beyond communications and content, NGOs can use prompt engineering for improving daily operations which might include things like internal training, meeting minutes summarization, translation of documents, etc.
Use Case: Meeting Notes to Action Items. Nonprofit teams often have planning meetings, board meetings, etc. If you feed the transcript or notes, the model can summarize and extract action items. For example: “Summarize the key decisions and list action items with responsible persons from the following meeting notes:” [paste notes]. The output: bullets like “Decision: Focus next fundraiser on online campaign. Action: John to draft campaign plan by Oct 1.” etc. This is enormously helpful for busy teams to ensure nothing is missed. It’s basically automating minutes drafting.
Use Case: Internal Training Material. NGOs have to train staff or volunteers on certain protocols (like child protection, safety, or how to use a database). If you have a dry policy text, you could prompt: “Create a simple bulleted checklist of do’s and don’ts from our 5-page Volunteer Safety Guidelines document:” [paste salient parts]. This yields a handy reference sheet volunteers can use. Or “Generate 3 quiz questions (with answers) to test understanding of our Code of Conduct.” (The model will come up with relevant questions and answers, which you can then refine.)
Use Case: Project Management Templates. Perhaps you need to create a project plan. You can ask: “Provide a template for a project plan for an NGO project including sections: objectives, activities, timeline, responsibilities, indicators of success.” It will output a structured template with placeholder text. Then you fill in your specifics. This ensures you didn’t forget a section and gives a professional looking structure.
Use Case: Simplifying Technical Information. NGOs might have technical reports (like an evaluation report with lots of data) that they need to summarize for their board or donors. Using prompt techniques to make it more digestible falls under prior summarization, but operationally, it means less staff time rewriting dense info.
Use Case: Email and Document Translation. Many NGOs operate in multilingual environments or collaborate internationally. Quickly translating emails or documents via prompt (like, “Translate this partner report from French to English in a formal tone”) helps staff overcome language barriers swiftly(nonprofits.freewill.com).
Use Case: Idea Logs and Knowledge Management. Suppose an NGO has a knowledge base of past project learnings. You could query it with a prompt like, “Summarize any lessons learned about community engagement from our past 3 project reports:” and paste excerpts. The model will unify them into overarching lessons. This is knowledge management – making internal information more accessible.
Use Case: Routine Writing. Think of operations like writing standard operating procedures, writing emails to schedule meetings, drafting MoUs between partner orgs, etc. These can all be templated by GPT. For instance: “Draft a Memorandum of Understanding between our NGO and Local School, outlining that we provide weekly workshops and the school provides space, duration 1 year.” The model can output a formal MoU structure. You’d only need to adjust specifics, but it catches the formal language and structure that might be tedious to do manually.
In summary for NGOs, as with other fields, prompt engineering assists with both the outward-facing communications and the inward-facing operations. It helps a small team punch above its weight by handling first drafts, summarizing large texts, and ensuring communications are polished. Importantly, it allows staff to focus on strategy and relationship aspects, while the AI covers boilerplate and structure.
One special caution for NGOs: if dealing with vulnerable populations or sensitive stories, one must ensure the AI doesn’t accidentally include language that could exploit or violate consent (e.g., revealing identities when it shouldn’t). Always review outputs for ethical alignment (like privacy, dignity, accuracy). The AI might not know those boundaries without being told, so sometimes include in prompt “Do not include personal identifiers” or similar if needed.
By leveraging these tools, NGOs can more efficiently spread their message and run their programs, hopefully leading to greater impact on the causes they serve.
Having delved into many practical applications of prompt engineering, we now turn to the future: the emerging tools that enhance prompt engineering, how multimodal capabilities expand what we can do, and how organizations and workers can adapt (reskilling, etc.) to an AI-infused workflow. The final section, “Tooling Advances,” will discuss these evolving aspects and the broader outlook.
7. Tooling Advances
The landscape of prompt engineering is continuously evolving, not just in technique but in the tools that support and enhance interactions with LLMs. As organizations integrate AI into their workflows, a whole ecosystem of tools and practices is emerging to make prompt engineering more powerful, collaborative, and efficient. In this final section, we’ll expand on the user’s draft ideas around emerging tools, multimodal prompting, workforce reskilling, and the future outlook for prompt engineering and AI in knowledge work.
7.1 Emerging Prompt Engineering Tools
In the early days, prompt engineering simply meant typing clever prompts into ChatGPT. Now, we are seeing specialized software and libraries designed to help craft, manage, and optimize prompts, as well as integrate LLMs into complex workflows. Here are some notable developments:
- Orchestration Frameworks (Agents & Chains): Tools like LangChain have become popular for developers building applications with LLMs. LangChain allows you to chain prompts together, call external APIs or databases between prompts, and create LLM “agents” that decide which action/prompt to do next (ar5iv.org, ar5iv.org). For a non-developer, what this means is that more complex tasks can be automated. Instead of you manually doing a multi-step prompt process, an agent (using something like ReAct prompting under the hood) can do it. For instance, an “AI researcher” agent might take your question, search for information, summarize it, and then give you an answer, all orchestrated by these frameworks. This abstracts prompt engineering patterns into reusable components. Microsoft’s Semantic Kernel is another framework that helps integrate LLMs with external skills and memory, so it can plan and remember information across interactions (ar5iv.org).
- Templating and Prompt Repositories: As prompt engineering matures, saving and reusing good prompts becomes important. Libraries like Guidance (by Microsoft) provide a way to programmatically compose prompts with placeholders and control the generation (ar5iv.org). For example, you can define a prompt template in a file, and fill it with different data as needed (similar to how one uses templates in web development). There are also community-driven repositories (GitHub projects, etc.) where people share effective prompts for various tasks (“Awesome Prompts” lists). These tools help standardize prompt use within teams – for instance, an NGO could have a repository of prompts for different writing tasks that staff can pull from, ensuring consistency.
- AI Assistant Plugins and Integrations: Both OpenAI and others have developed plugin systems where the AI can use external tools (like browsing, calculators, or custom company databases) when needed. OpenAI’s ChatGPT has plugins that essentially extend what can be done via prompts (the model is prompted internally to use a tool when appropriate). This ties back to ReAct and agents. For a user, it means less manual prompting to get information the model doesn’t have – it might automatically fetch it. For example, with a web browsing plugin, instead of you summarizing an article to feed in, you could just say “Find out the latest GDP of Nigeria” and the model will actually do a web search and get the answer. These tools are still evolving, but blur the line between prompting and programming. From a prompt perspective, you might have to prompt the model to use the plugin (“Search for X” in your message), but often the integration is seamless in newer interfaces.
- Guardrails and Safety Tools: There are tools like NVIDIA’s NeMo Guardrails which allow developers to set up rules for LLM outputs (ar5iv.org). For instance, a guardrail might enforce that the LLM not discuss certain topics or always respond in a certain format for sensitive queries. While originally aimed at avoiding misuse (like avoiding biased or harmful content), they can also be used for business rules (like “don’t mention competitor names” in outputs, etc.). Essentially, these act like a safety net around prompt engineering – if the model’s prompt-based behavior goes off track, the guardrail catches it. For end users, many of these guardrails are built-in by AI providers (OpenAI has content filters, etc.), but in the future, custom guardrails might be something companies tune (like an NGO could ensure the AI never compromises a beneficiary’s privacy by setting that rule).
- Data Connectors and Indexes: Another class of tools focuses on connecting LLMs to organizational data. LlamaIndex (GPT Index) and vector database solutions fall here (ar5iv.org). They allow you to index a large set of documents so that when you prompt the system, it can retrieve relevant pieces of text to include in the prompt (a form of Retrieval-Augmented Generation we discussed). This is often invisible to the user – they just ask a question and behind the scenes the system finds the relevant doc passages and constructs a prompt with those included. But it’s worth noting because it changes how you might work: instead of manually finding and copy-pasting info into the prompt, these systems will do it for you. In enterprise settings, this is huge for internal Q&A (e.g., “ask the company handbook” or “search across all our research papers and answer”).
- Automated Prompt Optimization: Research and some tools are looking at AI helping to improve prompts themselves. There’s a concept of Automatic Prompt Engineer (APE) or using reinforcement learning to find the best prompt for a task (ar5iv.org). While not mainstream for everyday users yet, this hints that in future, you might just tell the system what outcome you want and it will iterate on prompt variants to get there reliably. Imagine you say “the output is not specific enough” and the system internally adjusts the prompt wording until the model consistently gives specific answers. This would make prompt engineering less trial-and-error for the user; the system does the trial-and-error. Such techniques are still nascent, but some products are heading that way.
For general information workers, many of these tools will be under the hood of the applications you use – maybe in MS Office’s Copilot features or integrated in platforms like Notion, etc., where an AI is built-in. You might not need to know LangChain or have a vector database, but understanding that “the AI can now use tools and recall info” helps you craft your requests more powerfully (e.g., “Graph this data for me” might become possible because the AI can call a graphing function).
The upshot: the prompt engineering “environment” is becoming richer. It’s not just one model and one text box – it’s models plus memory, plus tools, plus guardrails. This means the outcomes can be more accurate, relevant, and context-aware, as long as these tools are configured correctly. Organizations adopting AI should look into these frameworks to supercharge how their employees interact with models. Early adopters (tech firms, AI startups) are already using chains and agents to automate complex tasks (like research assistants that read dozens of papers and produce a summary with citations).
From a skills perspective, while an end user might not code LangChain scripts, being aware of what’s possible means you can ask your IT or vendor for features that leverage these – e.g., “Can our AI assistant connect to our SharePoint files?” is a question that leads to integrating a data connector, enabling better answers with context.
7.2 Multimodal Prompting (Beyond Text)
Up to now, we mostly talked about text prompts and text outputs. However, AI models are expanding into multimodal capabilities – meaning they can accept and generate different types of data: images, audio, video, etc. The most recent development is models like GPT-4 having a “vision” mode that can analyze images in prompts (learn.microsoft.com). Let’s explore what multimodal prompting allows and how it might be used.
- Image Inputs: With models that have vision (like GPT-4 Vision, or others like Google’s PaLM 2 with image understanding), you can prompt by providing an image and asking questions or for descriptions. For instance, an information worker could use this to analyze charts or diagrams. You could show it a chart screenshot and ask, “What trends do you see in this graph?” and it can respond with a summary (e.g., “The graph shows a steady increase from January to June, then a slight dip in July (learn.microsoft.com).”). In a more everyday scenario, you could snap a picture of a form or a business card and ask the AI to extract the text (OCR) or summarize it. Vision-enabled models bring the ability to OCR and interpret images: they can identify objects, read handwriting, describe scenes (clarifai.com). For example, an NGO communications team might feed a model an infographic and ask “Please draft alt-text for this infographic” (for accessibility), and the model can do that because it ‘sees’ the infographic.
- Image Outputs: Generating images from prompts is not GPT-4’s domain exactly (that’s DALL-E, Midjourney etc.), but integration is happening. Already tools like MS PowerPoint’s upcoming Copilot will likely allow “Generate an icon of hands holding a globe” and an AI image model will produce it. So multimodal in that sense: you prompt, and the output could be an image. This broadens what we can create with natural language prompts beyond text documents: one can create graphics for slides, marketing materials, etc., by just describing them. We must note the quality and specificity control in image generation is its own art (“promptography” as some call it). But basic business graphics or concept art are very feasible now.
- Audio and Speech: Another mode is prompting via voice or getting audio output (text-to-speech). Already, tools like Siri or Alexa have primitive versions, but with LLMs, voice assistants will become much smarter. You might speak a prompt instead of writing it (“Summarize my unread emails from today”) and it speaks back the summary. Or you could feed an audio file (like a recorded meeting) directly to an AI to summarize or extract tasks. Whisper (OpenAI’s speech recognition) combined with GPT can do such tasks: audio in, summary out. For language learning or communications, multimodal might mean you can ask the model to speak a response in a certain accent or emotion. For example, “Read this reply aloud in a calm tone.” Not common yet in everyday apps, but likely soon.
- Video and Other Modes: This is more speculative, but models are being trained that can analyze video (like summarizing a meeting recording or a training video). For now, those are separate systems or require breaking video into frames or transcripts. But future multimodal AI could allow prompt like: “Here’s a training video [link]. Make a written checklist of the procedures shown.” The AI would “watch” and output the checklist.
From a prompt engineering perspective, multimodal means:
- You can reference or include different data: “In the image below, [insert image], what do you observe about X?” The model’s prompt now includes a non-text element it can interpret【19†Image】.
- You might have to specify output mode: e.g., “Describe this image in 50 words” (text output) vs “Create an image of X” (image output).
- The ability to process images means you might not need to painstakingly describe a complex diagram; you can just show it and ask questions.
For information workers, consider:
- UI/Design: If you’re a designer or product manager, you could show an app screenshot and ask “What usability issues do you see?” The AI might point out things like low contrast text or confusing labels. It’s like a quick heuristic evaluation.
- Excel charts or PDFs: Instead of copying numbers, show the PDF page or chart and ask for analysis or summary. Saves steps.
- Troubleshooting: A field technician could send a photo of a machine part to an AI to get troubleshooting steps (“Based on this broken part image, what likely caused it?”).
- Content creation synergy: One could prompt, “Generate a tagline image with text ‘Save Our Oceans’ overlaid on an ocean background” – and get a ready social media graphic, blending text and image generation.
The line between text and other content is blurring. The term “prompt” itself is expanding to mean any input to an AI, not just textual. So prompt engineering in the future includes how you frame image inputs or audio inputs too. For instance, telling an image model to use a certain art style is like telling the text model to use a certain tone. We will have guidelines like “for professional infographic style, do X in prompt” similar to how we do with text tone now.
7.3 Workforce Reskilling and Adaptation
With AI tools becoming co-pilots in many tasks, roles in the workplace are evolving. People worry about AI replacing jobs, but equally there’s a shift where new skills (like prompt engineering, evaluating AI outputs, and working alongside AI) become important. Reskilling the workforce is a priority many organizations are talking about (mckinsey.com).
- New Roles: Prompt Engineer / AI Wrangler: We’ve seen companies hiring “Prompt Engineers” especially in AI-heavy firms. These are people who specialize in designing optimal prompts and workflows to get the most out of AI. McKinsey’s survey found about 7% of companies using AI had already added prompt engineering roles (mckinsey.com). We expect this to grow (mckinsey.com). However, outside of tech companies, the role might not be separate; instead, existing roles get augmented with these skills. For instance, a marketing specialist might become the in-house expert on using AI for copywriting, effectively doing prompt engineering as part of their job.
- AI Literacy for All Employees: Knowing how to ask AI the right questions and how to verify its answers is becoming a baseline skill. Just like basic internet search or Excel skills are expected in many jobs, prompt literacy could be next. Companies are beginning to train staff on using tools like ChatGPT effectively for their domain tasks (email drafting, coding help, research, etc.). Those who adapt can massively increase productivity, as evidenced by that MIT study where using ChatGPT boosted output by ~37% (exec.mit.edu). We might see internal workshops or centers of excellence where employees share prompting tips and successful use cases.
- Focus on Judgment and Higher-Level Tasks: As AI takes over drafting and initial analysis, human workers will spend more time on reviewing, strategy, and complex decision-making. For example, instead of an analyst spending days building a report from scratch, they get an AI draft in an hour, then spend their time validating findings, adding proprietary insights, and shaping the narrative for the audience. Their analytical judgment is still crucial, but the grunt work is minimized.
- Reshaping Job Descriptions: Roles like executive assistants, customer support agents, or content writers are already being reshaped. An executive assistant might become an orchestrator of AI tools—scheduling or summarizing meetings with AI help, drafting emails via AI, etc., managing more tasks simultaneously. Customer support agents might handle fewer simple queries (if AI chatbots field them) and focus on complex cases requiring human empathy or creative solutions. But they also need to learn to supervise AI – e.g., checking chatbot logs for correctness, or feeding the bot new info.
- Training on AI Ethics and Policy: Another aspect of reskilling is understanding limitations and ethical use of AI. Workers should learn when not to trust the AI, how to detect AI-generated errors, and issues like bias or confidentiality. Many companies will establish policies (like “Don’t paste sensitive client data into a public AI service”) and employees must be trained on these. So digital literacy now includes AI literacy and ethics.
- Reduction of menial tasks increases need for soft skills: If AI helps reduce paperwork and drafting, roles might emphasize interpersonal skills more. In NGOs for example, if proposal writing is made easier by AI, fundraisers can spend more time cultivating donor relationships. That requires empathy, listening, persuasion – things AI can’t replace. So ironically, as AI handles “hard skills” like generating content, “soft skills” become even more the differentiator for human workers. Being creative, empathetic, strategic – those are where humans will focus.
- Reskilling at Scale: According to McKinsey, about 40% of companies expect to retrain a significant portion of their workers (>20%) in AI skills in the next few years (mckinsey.com). This is an encouraging sign that instead of laying off due to AI, many firms prefer to upskill their people to work with AI. So we’ll likely see a wave of training programs, possibly certifications in prompt engineering or AI collaboration. In some cases, we see it already: online courses on “ChatGPT for Business” are popping up.
- Career Opportunities: People who become good at using AI tools can leverage that to advance. For instance, a content writer who can output 4x as much high-quality content with AI assistance may take on more strategic editorial responsibilities. A data analyst who masters AI may become a “citizen data scientist”, tackling projects previously requiring a bigger team. Essentially, mastering prompt engineering can be a career booster, making one the “go-to” person in their department for AI-powered productivity. It’s like being the Excel guru of the 2000s, but for AI in the 2020s.
In summary, the workforce is not so much being replaced wholesale as it is being augmented. Those augmentations mean the human role shifts: less drudgery, more oversight, creativity, and ethical judgment. But to get there, companies and individuals need to invest in learning and adapting. This is a change management challenge as much as a technical one.
The concept of “AI co-pilot” is useful: think of the AI as a junior colleague who is super fast but somewhat inexperienced – it needs your guidance and checks, but if you manage it well, your whole team (you + AI) is far more productive. Training people to effectively manage their AI co-pilots is a reskilling goal.
7.4 Future Outlook
Looking ahead, what is the future of prompt engineering and the role of LLMs in general information work? It’s a dynamic space, but we can make some educated projections:
- Prompting might become more conversational and less literal: As models improve and incorporate more context automatically, users might not have to carefully engineer single prompts as often; instead they might engage in a back-and-forth and the system will handle context. For example, instead of writing a giant perfect prompt, you might just start the conversation normally and the AI behind the scenes figures out an optimal prompt path (this links to the automated optimization earlier). Already ChatGPT’s multi-turn memory reduces needing to restate everything each prompt. Future interfaces (like autoGPT or others) could handle entire goals (“Help me create a marketing plan”) by decomposing into prompts internally. So, the skill might shift from writing one clever prompt to effectively managing a dialogue and giving good feedback to the AI on each turn.
- Less “prompt engineering” for straightforward tasks: As LLMs incorporate larger contexts (like 100k tokens or more) and have more knowledge, you may not need to work around their limitations as much. For instance, once an AI can take in an entire book, you don’t have to summarize it chapter by chapter to discuss it. That reduces complex prompt steps. Also, alignment improvements (making models follow intents better) could mean the model “just gets” what you mean with less magic wording like “Let’s think step by step.” (That phrase might become obsolete if the model is inherently reasoning well or doing chain-of-thought under the hood for any tricky question.)
- However, high-level prompt skills remain vital: Even if basics get easier, using AI to its full potential on complex projects will require an understanding of how to break tasks down and give the right instructions. So advanced prompt engineering might move “under the hood” for common use, but power users and AI developers will still refine prompts for maximal performance in critical applications. Also, domain-specific prompting might emerge – e.g., techniques that work best for legal vs. medical contexts, etc., and those with domain knowledge + AI skill will be in demand.
- Standardization and Best Practices: We might see standardized prompt patterns or even markup languages for prompting (some exist in research). Companies may develop internal style guides for prompts (“Always start with context section, then task, then output format”). There could be more formal training in prompt techniques (some universities are already integrating AI writing into curriculum). Perhaps certifications like “AI-assisted Project Management” where prompt use is part of it.
- AI Alignment and Control: On the flipside, as models become more autonomous, ensuring they stay under human control and aligned with our goals is crucial. Prompt engineering is one tool for alignment (you word instructions to avoid ambiguity or misuse). We might see governance structures in workplaces: e.g., a requirement that a human review certain AI outputs (similar to code review) especially in sensitive matters. So, the future might involve processes where AI drafts must get sign-off – prompt engineering plus human oversight integrated.
- New Interfaces beyond keyboard: As voice and AR/VR interfaces come in, prompt engineering might involve speaking or even demonstrating. For instance, maybe in a design tool you sketch something and say “like this, but more modern” – a multimodal prompt combining action and words. In AR glasses, you might look at a machine and ask via voice for maintenance history. So, prompting may become more fluid than typing sentences – but the underlying skill of specifying your needs clearly remains, just expressed differently.
- Integration into daily tools invisibly: The ideal future is AI assistants in all our tools that require minimal prompting for routine tasks. E.g., your email client suggests drafts or triages mail, your IDE auto-completes bigger chunks of code, your spreadsheet explains trends, often without you explicitly asking because it predicts needs. Prompt engineering in such cases might be more about confirming or adjusting AI suggestions than asking from scratch. But when doing new or non-routine tasks, you’ll still formulate queries to the AI.
- Continuous Learning: LLMs might get real-time or frequent updates (some already do with retrieval or fine-tuning). If they stay up-to-date, prompts can reference current events or latest data and the model will respond accurately (reducing the current recency problem where it might say “as of my last update in 2021…”). That means by 2025 and beyond, we may treat them even more like dynamic knowledge bases. The better they get, the more we trust them with critical analysis (with caution).
- AI in Decision-making Loops: In the future, AI might not just recommend but also take certain decisions autonomously for efficiency (with oversight). For example, an AI managing inventory reorders supplies when low (common in narrow AI already). LLMs could extend that to more complex “decisions” like routing a support ticket or drafting a policy. Humans then play more of a governance role – defining policies for the AI (which in a way is like prompting at a higher level – writing meta-prompts that instruct the AI on how to handle classes of situations).
- Creative Collaboration: On a bright note, as mundane work gets lighter, humans can be more creative and strategic. AI might even help spark creativity (like brainstorming weird ideas you wouldn’t think of). So, the future workplace could be more fulfilling if managed right – letting humans focus on what they find meaningful while AI handles the slog. But that requires thoughtful implementation; otherwise we risk either misuse or people feeling disengaged if they’re just supervising robots all day. It’s a balance to strike.
Finally, it’s worth recognizing that AI will continue to surprise us. New models (like GPT-5 or others) might change the game again. Perhaps prompt engineering as we know it becomes less prominent if AI truly understands intents from minimal input (the holy grail of natural language). But until then, and likely even after, the ability to communicate effectively with AI systems will be a key skill – much like communication with other humans is.
In conclusion…
…prompt engineering is both an art and science that is democratising access to AI’s capabilities. By mastering it, individuals and organizations can unlock tremendous productivity and creativity, stay competitive, and better achieve their goals – whether business outcomes, research breakthroughs, or social impact. The tools will keep advancing, but the core principle remains: clear guidance yields better outcomes. As we embrace these advances, pairing human judgment and values with AI’s power will be critical to ensure we use this technology responsibly and beneficially.

Sources:
- Schulhoff et al. (2023), The Prompt Report: A Systematic Survey of Prompting Techniques – for taxonomy and advancements in prompt methods(ar5iv.org, ar5iv.org).
- Amatriain (2024), Prompt Design and Engineering: Introduction and Advanced Methods – for fundamentals of prompt construction and advanced techniques like CoT and reflection (ar5iv.org, ar5iv.org).
- OpenAI & others (2023), various documentation and blog posts – for best practices, e.g., clarity and examples in prompts (medium.com, medium.com).
- McKinsey (2023), The state of AI in 2023 & explainer articles – for insights on workplace impact and need for reskilling (e.g., 40% companies retraining >20% workforce) (mckinsey.com) and economic potential of AI (mckinsey.com).
- MIT (Noy & Zhang, 2023 in Science) – study showing ~40% reduction in task completion time using ChatGPT (news.mit.edu), highlighting productivity gains.
- Yao et al. (2023), ReAct: Synergizing Reasoning and Acting in LLMs – demonstrating tool use via prompting and reduced hallucination (arxiv.org, promptingguide.ai).
- Various NGO-focused resources – for practical uses in fundraising and communications (ccsfundraising.com, nonprofits.freewill.com).
Note: This report was prompted with ChaGPT’s DeepResearch and human-checked and refined afterwards.